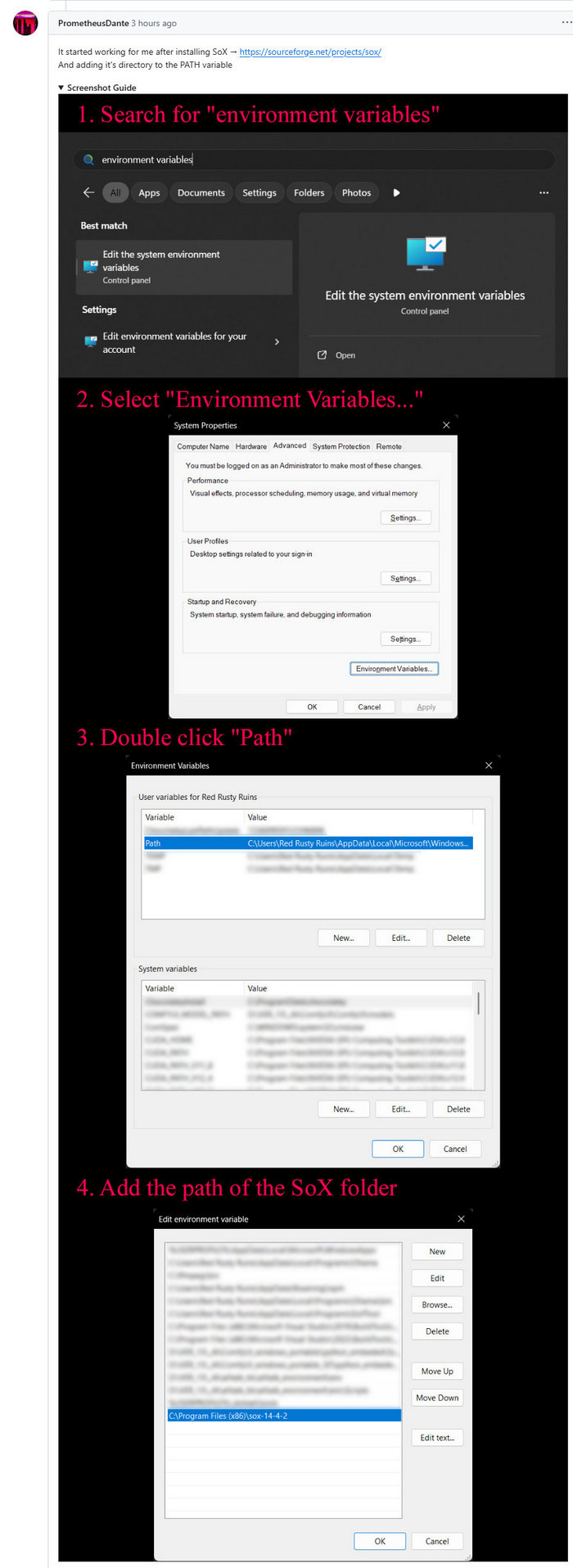
The Future Vision XPrize is now live, a $3.5 million film-making contest. Submit a three minute trailer for a film that tells a story about an optimistic future. Specifically, show how good things will become real in a technologically-advanced future that is happening because of us (not being done ‘to us’). Animation and AI tools can be used. Deadline: 15th August 2026.