Welcome to another pick of Poser and DAZ Studio items released last month. Also some software picks at the foot of the post. As usual I don’t feature items that are not ‘commercial use for renders’, and I shy away from the great-looking but heavyweight/expensive ‘HD’ items for DAZ.
Science fiction:
An unusual cyber-Medusa Cyber Hair Kit and Script for Genesis 9.

Porter robot, for Poser and DAZ.

Black UFO for Bryce. Free.

A convincing near-future Mars Beetle transport and matching Mars Base. Which could also be a Moon Base. Both free. For interiors see the Hostile Surface series from Coflek-Gnorg, for Poser.

Free, a Totem Serge model which, when glowing and grouped in an avenue, could suit sci-fi scenes such as Moon Base landing strips.

Princess Series Star Explorer Outfit, a good-looking near-future dark spacesuit for G9F.
AB Simple Artificial Skins and Shaders for Genesis 9, suitable for alien humanoids.
Gothic and horror:
LOWREZ Zombies for DAZ Studio. Three groups, for massing in the scene.

Steampunk:
1971s’s Airship with interior for Poser. Also available for DAZ.

1971s’s Sky Boat, now available for DAZ Studio.

120 Metal and Alloy Materials for E-on Vue.
Fantasy:
Palantiliths 2026, a remake of the old ones.

Nobleman’s Cradle for DAZ.

Storybook:

Hr-282 for Poser and V4.

COS Mae for Genesis 9, a juvenile-delinquent / bully girl character.

Toon:
RA Maisie Scifi for Poser (requires Masie figure). Also a clothing tutorial.

Masie Sci-fi probably flies the cute new ScoTT-00 flying machine.


Semi Faceless for Genesis 9. Potentially useful for comics, where you want to draw in the eyes / mouth yourself.
Figures and parts:
Width Adjusters for Genesis 9 Female. New characters, with a simple width slider.

Long leg morphs for Genesis 9 Female.
Hair Helper for Genesis 9. Free.
dForce FV Messy Rogue Hair for Genesis 9. Nice multi-purpose male hair.

Conforming Flak Vest for M4. The default M4 is seen in the preview, but know that an M4 doesn’t have to look so boring.

A general-purpose free Conforming Hoodie for LaFemme 2 for Poser.
Shaders:
Energy Effects VFX shaders for DAZ.

Silvia Shaders for DAZ, including a ‘thick fur’ and ‘lava’.
120 Metal and Alloy Materials for E-on Vue.
Landscapes and environments:
Mountain Stone House: Pool by the quality texturer ShaaraMuse3D.

Urban Weeds for DAZ.
Animals:
Short Faced Bear by AM for DAZ.

Theron The Wolf, a great semi-stylised wolf for DAZ and you need the base DAZ Dog 8. Currently on its introductory discount at a very reasonable $12.

Need a yappy mini-dog? Meet Abbey Rose for DAZ and Poser. In China, also know as “lunch”.

Free Cat Zeus Poses, including a chase pose for chasing the annoying Abbey Rose.

Nature’s Wonders Butterfly Garden 2. Butterflies and also their natural habitat plants.

Songbird ReMix Magpies and Orioles of the New World (plus a free nest) and Blackbirds & Grackles. For Poser and DAZ.

Songbird ReMix Cowbirds. For Poser and DAZ. Free!

Nature’s Wonders: Flies. For Poser and DAZ. Also a free Nature’s Wonders Fly Swatter.
Historical:
Porto Bella, a Venetian style town by Stonemason. See also the new KuJ Courtyard.

dForce Traditional Peruvian Woman’s Outfit for Genesis 9.

A Chinese Rickshaw for Bryce. Free.

FG Outbuilding interior from rural America in the 1920s/30s/40s.
WW2 C8A truck poses for Genesis 9. 22 World War Two poses for a truck team. Free.
Launch Tower for Bachem Natter Rocket Plane.
Vintage Guitar and Amp 2 for DAZ.

1970s Asymmetric Blowout Hair for Genesis 8 and Genesis 9.

Scripts and helpers:
Bluegene’s Talk Designer Viseme files for V4-M4. Free. The files enable V4/M4 to talk with TTS and lip-sync.
Automatically rename multiple cameras in DAZ.
Animation Doctor – Motion Control, speed up or slow selected keyframes in DAZ. Also, insert / delete frames anywhere on the timeline.
Tutorials:
How to include lots of fully posed, clothed figures in a Poser or DAZ scene.
Bad design practices to avoid at all costs, when creating 3D scenes in Poser or DAZ Studio.
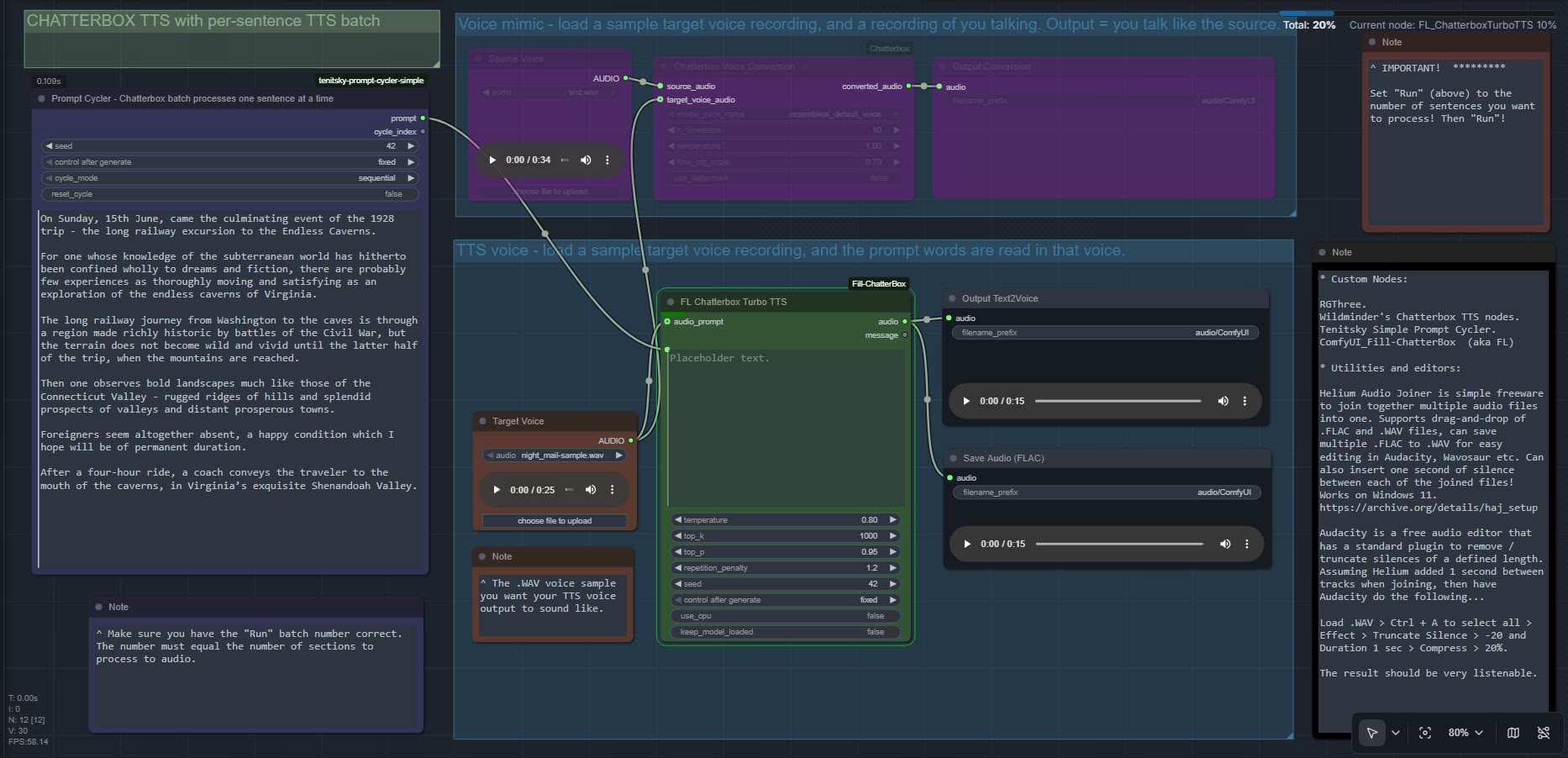
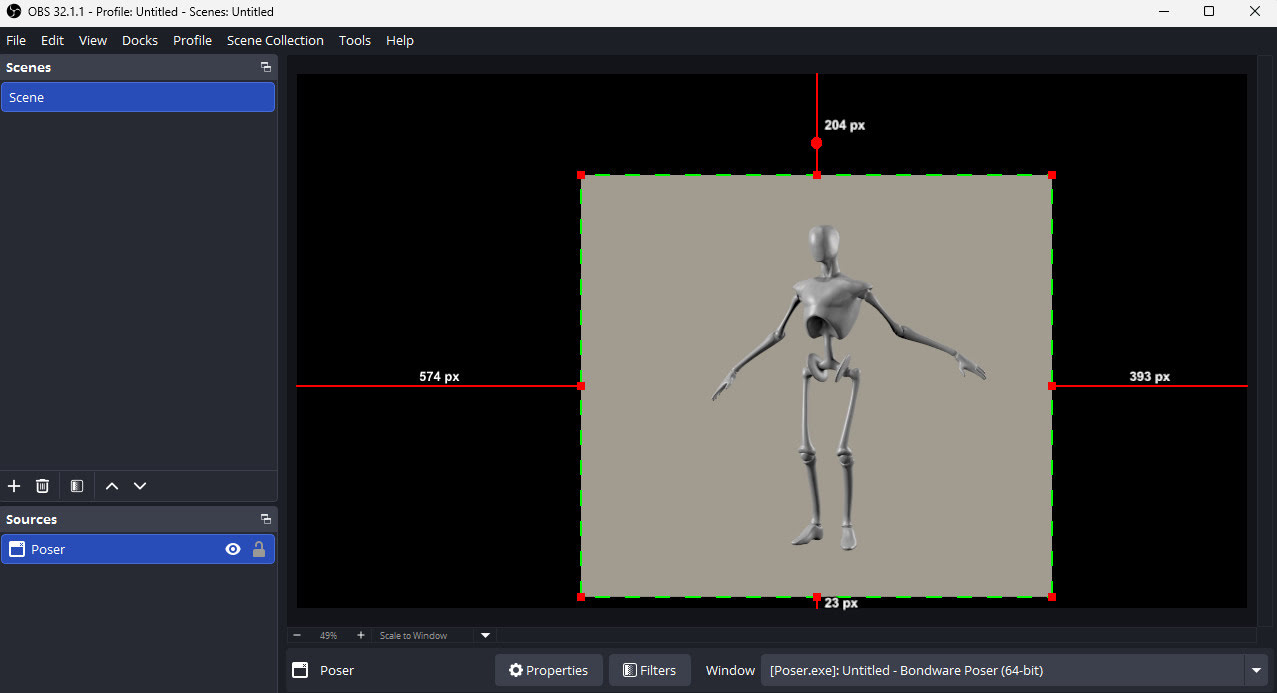
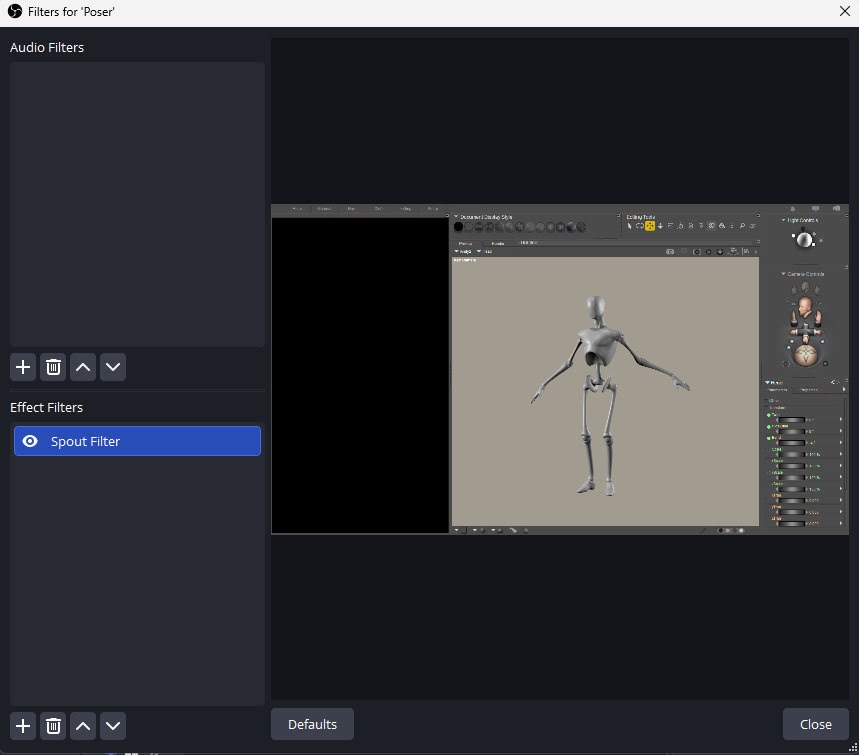
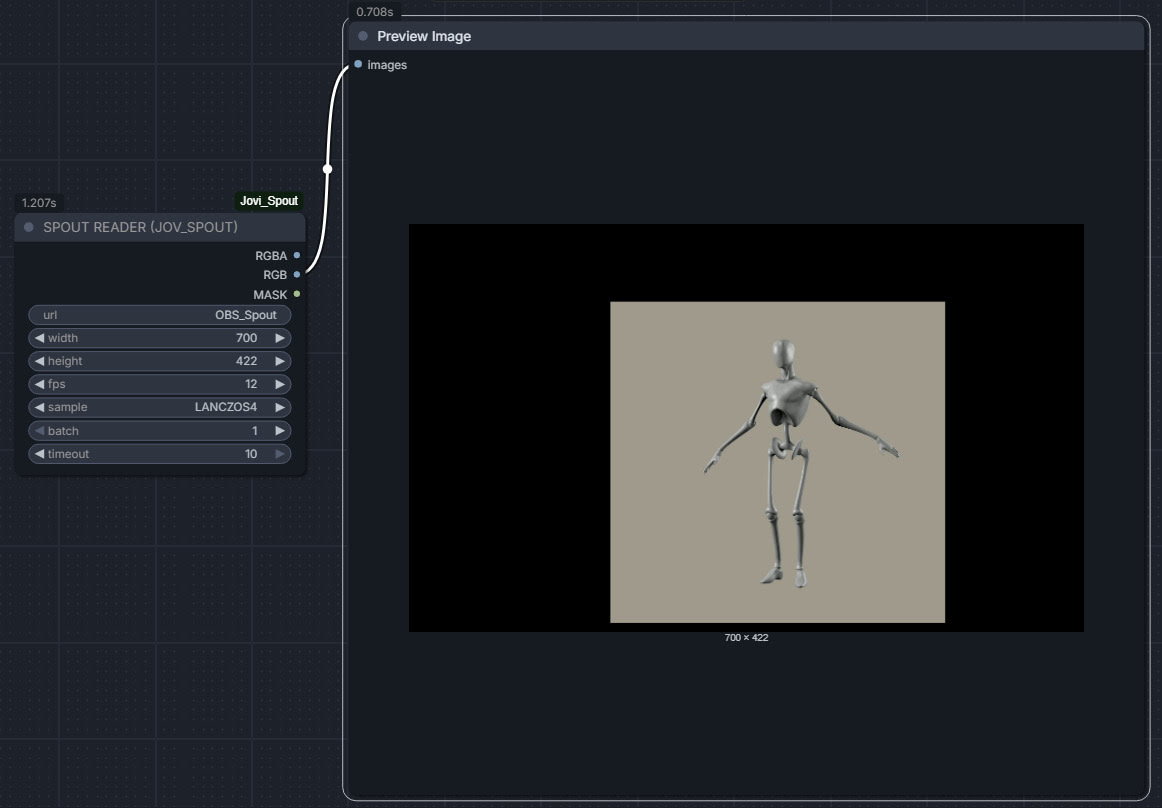
My failed experiment, using OBS Studio + DAZ/Poser viewport capture via Spout to get a Poser viewport live in ComfyUI.
Software:
Poser 14 was reviewed in the latest Imagine FX magazine. A positive review, but let down a bit by hasty screenshots and by having no mention of Poser’s unique Comic Book Preview mode (the issue was comic-book creation themed).
The venerable 3D software LightWave 2026 is now in beta, with the full release set for the end of May 2026.
Another 3D sculpting freeware, which runs offline and for the desktop PC, Tamga. Aims to be simple and intuitive to use, unlike ZBrush.

Japan’s Clip Studio Paint Version 5.0 has been released. This over-complicated and fiddly comic-book production software now has: built-in 3D hand models; the ability to draw your own guide-lines on the basic 3D figure mannikins; and at last you can now group 3D items in a scene and move them as one.
DaVinci Resolve 21 (beta), with new AI features.
The freeware NaturalVoiceSAPIAdapter lets you install and run Microsoft’s Azure ‘neural’ TTS voices locally, running them offline as if they were standard SAPI5 TTS voices. What’s new is that the latest version now supports Windows 7. There’s also a new video showing the secret control-codes you can use with these offline Microsoft Azure TTS voices in Balabolka.
Talking of audio and TTS, who knew that the go-to editing freeware Audacity can run Python scripts?
Dimensions 2 Folders. Windows freeware to auto-sort images into sub-folders, based on their dimensions.
A simple .JSX Photoshop script for zooming in to a set zoom level. No advanced AI could provide me with a working script for this, not even Grok. It means no more wrestling with that infernally slippy Navigator window/slider, if you have images of a set size and consistently need to get them loaded up at a specific zoom level. e.g. eBay postcards at 1600px, where the right-hand side of the card gets hidden under panels at the default zoom-level. Tested and working.
Generative software:
All free, as is the way of local AI tools.
ComfyUI-Image-Conveyor. A drag-and-drop UI to visually ‘queue up’ many images, for the workflow to then process one at a time.
For those with powerful graphics-cards, a free custom node that integrates the OpenCut video-editor freeware into ComfyUI.
A standalone local LavaSR-Fast-Enhancer with GUI, for quickly and automatically cleaning up noisy audio recordings.
Also, note that the free 400 credits a month at the ComfyUI Cloud doesn’t start on the 1st of the month, as you might expect. More like on the 8th of each month. So, don’t panic if it doesn’t roll over on the 1st. Update: Offer no longer functions, mid May 2026. “Subscription required” to run workflows, now, despite having free credits.
Censorship:
Those of us in the UK are now completely blocked from the popular Imgur image-hosting service, widely used on Reddit. It’s also now effectively impossible for us to access the full version of CivitAI (Google sign-in/sign-up doesn’t work if using a VPN). Both blocks are the result of our dismal government. I hear that the Russians have also completely blocked their citizen’s access to DeviantArt, along with many other websites.
Adobe-AVX2-Patch. Adobe software installers now throw a tantrum and refuse to install if your old PC’s CPU doesn’t fully use AVX2 extensions. Sometimes it will refuse even if it’s an old PC that does support AVX2. Yet their software, such as Photoshop, runs fine without AVX2. Bypass this nannying nonsense with a handy patch.
That’s it for April 2026. More picks next month!