Google has announced that Google Chrome browser users will not be allowed to install their own choice of plugins, addons, and userscripts, from January 2014. Today I moved over to using Firefox, as a result. Here are my notes on the “how to” of the move from Chrome to Firefox, in the hope the notes may help a few others:
1. Backup any old bookmarks from any existing install of Firefox. It seemed best to start fresh, so I removed the old version of Firefox via a full uninstall.
2. Download and install the very latest Firefox. As this was a fresh install, the first time Firefox loads it should offer to automatically port over all your bookmarks, toolbar bookmarks, passwords, etc. from Chrome. (The tiny favicons will only reappear, next to bookmarks on your toolbar, when you revisit those bookmarked pages).
3. Tweak the Firefox interface. I prefer to get back to a retro look with Classic Reload-Stop-Go Buttons.
Then go View | Toolbars | Customize. While this Customize library window is open, you are able to drag around the navigation icons in the navigation bar. Get the icons positioned how you want them, then before you close the Customize library window choose “Icons + Text”. Then click “done”. This is how I like the top left on my browser…
4. Get the RSS newsfeed icon back in the address / location bar by installing this addon. The RSS button it adds had success in passing over the feed to my free desktop RSS news reader Feeddemon.
5. Add some basic advert and click-jacking blocker add-ons:
Adblock Plus
Flashblock
NoScript (annoying initially)
And then in Firefox go to: Tools | Addons | Plugins and disable all the craptastic media-player plugins that ship with Firefox (RealPlayer and the like, ugh). I only left Flash on “Always Activate” — since the Flashblock add-on (above) keeps it under control.
6. Then block the web’s other annoyances with these add-ons:
Facebook Purity (and import any blocklist / settings from your Chrome version of F.B. Purity)
Comment Snob
7. Add userscript capability to Firefox:
Greasemonkey (required for running all userscripts). Followed by…
GoogleMonkeyR. Vital for working with Google Search, in my opinion. I set it up to display results in three columns, and also to block several bits of Google Search cruft.
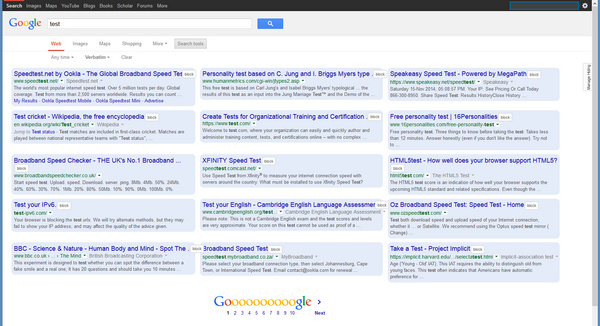
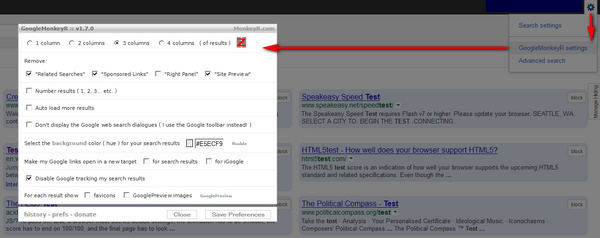
(To find GoogleMonkeyR settings: make any search in Google, then right-click on the grey cog. Bear in mind that ticking “Don’t display the Google Web Search dialogues” may prevent the search box appearing above the top of search results in Google Images, and Google Books).
Direct Links in Google Search. This forces direct URLs to be used in the search result links.
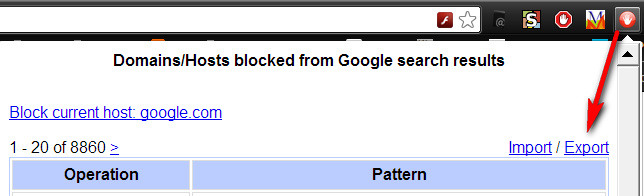
Google Hit Hider by Domain (blocks Google Search results by unwanted domain). Import your old Google Search blocklist from “Personal Blocklist (by Google)”, then use the de-duplicate tool in Google Hit Hider…
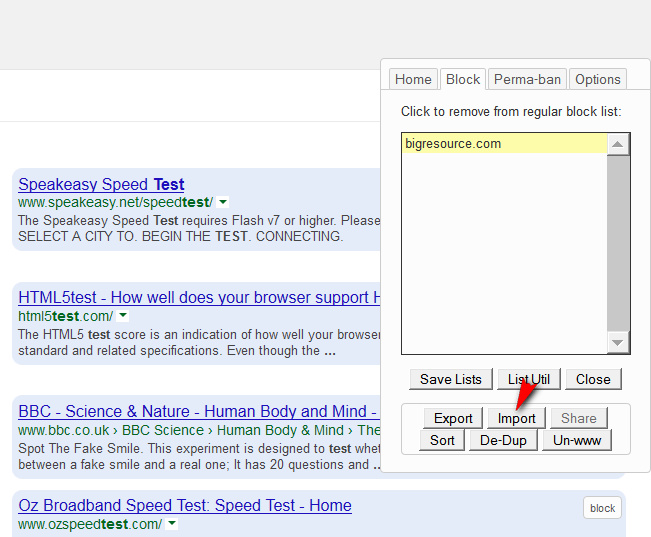
8. Finally, go to Tools | Options | General | Home Page. There paste in this handy home page URL, which will send you to the main Google Search when you click on the Home button in Firefox:
https://www.google.com/webhp?hl=en&complete=0&tbo=1&num=18&tbs=li:1
This special URL has certain parameters embedded in it, which:
* forces Google Search to use Verbatim (it searches on just what you type, not what it guesses you might want)
* sets the number of results to 18 (perfect with a widescreen monitor and GoogleMonkeyR using three columns)
* forces the top Search Tools open, displaying drop-down items
* forces Google Search to use its complete main USA index, without making an automatic switch to a local version
* and turns Google Search’s Autocomplete off.
It also seems to have the advantage of turning off nagging on the Google Search front page, re: “we use cookies!” and “download Chrome now!”.
The resulting ad-free nag-free search results layout, with GoogleMonkeyR and the above fixes:
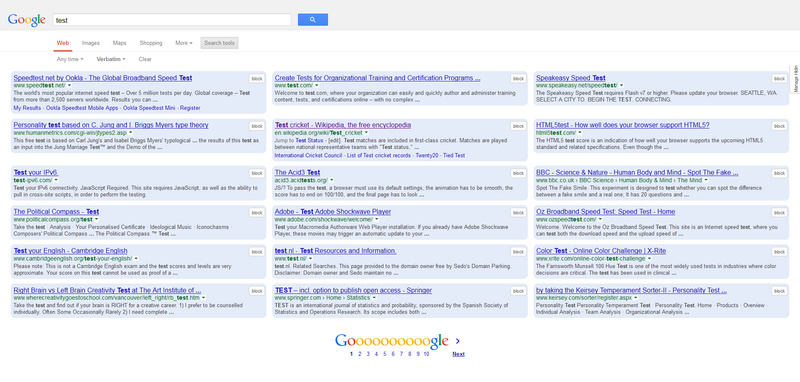
9. You can use the same URL trick with a Google News search, dragged onto your bookmarks bar, thus:
https://www.google.com/search?hl=en&gl=uk&tbm=nws&authuser=0&q=keyword&num=18&tbs=sbd:1
Replace the keyword in the above URL with your own. Switch out “uk” for “us”, etc.
Also handy is this Google Books link, with parameters included:
https://www.google.com/search?lr=lang_en&tbo=p&tbm=bks&q=%22beautiful+roses%22&tbs=,bkv:p,bkt:b&num=12
10. Other Firefox add-ons that are also very useful:
* the free grammar and spelling checker After the Deadline + Menu Editor to reverse AfterTD’s impudent hijacking of the top of the right-click context menu in Firefox. Sadly there’s no way to have AfterTD use British English spelling.
* Google Translator for Firefox.
* Paste Email Address
* Make Link
* FEBE Backup
* Bookmark Favicon Changer 2.0 (is the only one that works with the latest Firefox)
* Instasaver (Instapaper saver button for Firefox) (works with the latest Firefox including Nightly developer version, requires an Instapaper account)
* NoSquint (a nice flexible and easily resettable zoom tool)