How to replace Instapaper or Pocket on a Windows desktop, with no Cloud service required:
1. Install the Web browser addon Save as eBook from the Chrome store. This adds a neutral little button icon next to your Downloads icon.
2. When you visit an article in a magazine or newspaper, place your cursor at the top or bottom of the article and then drag to manually select the headline and text. Using the new addon, then “Add selection as eBook chapter”. The selected article is saved locally in the addon. It can handle scholarly-sized articles, and didn’t balk at a 14,000 word essay.
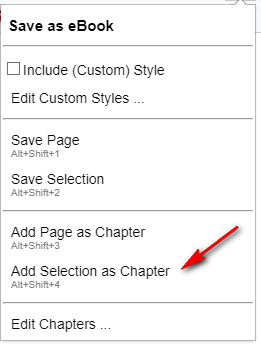
ALT+SHIFT+4 is the ‘Save as eBook’ keyboard shortcut command to save your selection. But who wants to do keyboard yoga with your fingers, when all you have is your hand on the mouse? In which case you can use mouse-gesture freeware such as StrokesPlus – with acSendKeys(“%+4”) (where % = ALT and + = SHIFT. It looks like this…
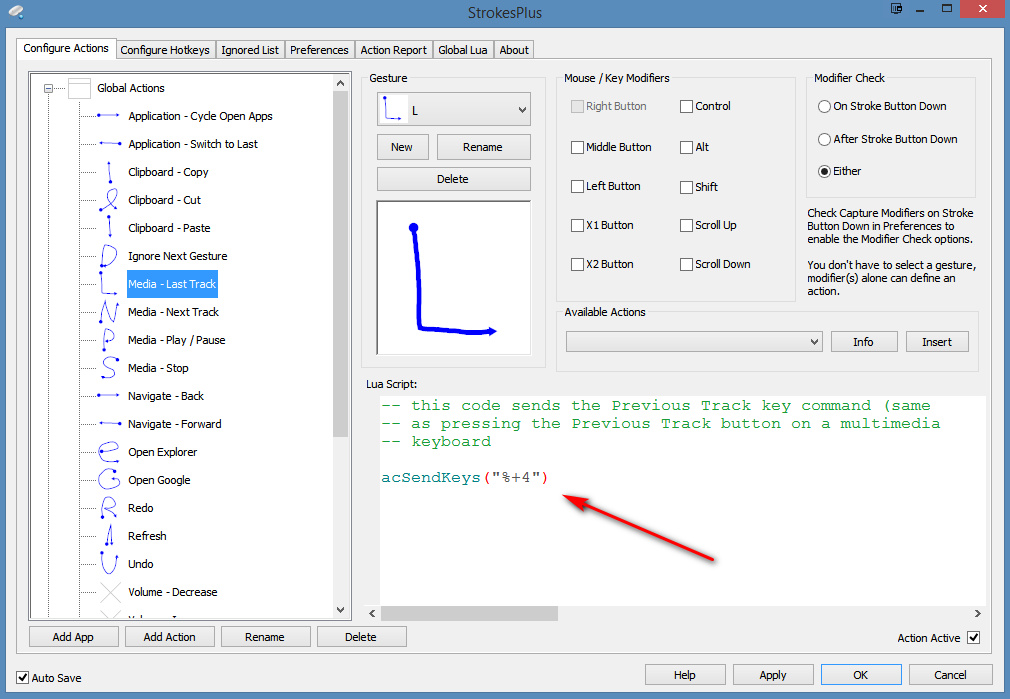
The “L” mouse gesture is easy to do, and to remember as it mimics the text selection process. Note this StrokesPlus gesture can only work if it’s in the Global actions folder.
3. When you have enough articles saved in that way (10, 15, 20, a week’s worth, whatever suits you), open the Chapter Editor via the addon. You can reorder the saved articles as you see fit, and then you press “Generate eBook”. Only .ePub output is supported, and each article is saved as a chapter. Having chapters is vital on a device like the Kindle 3 ereader, as it’s then easy to skip back and forth between articles rather than laboriously paging through.
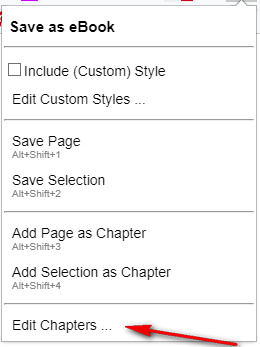
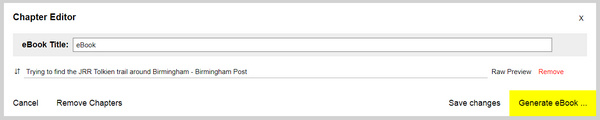
You can also title the eBook with a date.
4. Those using the older dedicated Kindle e-ink ereaders (rather than newer all-purpose Kindle tablets), and who want a Kindle .MOBI with chapters intact, can convert using the Calibre software. Chapter sections should be retained in the conversion. (If not, look at Settings in Calibre). Assuming you want a weekly batch of articles in a single file, then the Calibre .ePub > .Mobi conversion shouldn’t be too tedious to do.
5. Then either do… i) a manual USB transfer, ii) a local Wi-Fi transfer, or iii) an online “Send to Kindle…” operation from Windows.
6. When you’re ready to start saving another batch of articles, first delete the old ones from the addon.
There are a few drawbacks…
* There’s no automatic ‘readability’ detection of the body text, with stripping of page-fluff, ads, pictures etc. To do that you have to do a single sweep down the page to manually select the headline, byline and body of the article.
* Even then, it’s not possible to omit images from your selection. For instance by turning off image loading in your browser. The addon is obviously copying the underlying HTML code of the selection, not simply the visible text. That’s why it doesn’t work alongside ‘readibility’ or ‘read view’ addons. It’s calling the images from the HTML when it makes the eBook. The addon maker might usefully add a “Never save images” toggle, in future. And enable multi-part selections so as to skip mid-article text ads, or just select ‘headline/byline + several parts of the article’.
* You don’t make a ‘record’ of all the articles you’ve saved over time, other than in the form of the eBook output itself. There’s no .CSV list to download, with headline title, URL and suchlike, as there was with Instapaper. But if you archive the .ePub files, that serves as a full-text searchable archive.
* Nor is there any means of pushing your saved and linked article list to RSS for public consumption. But there are better link saving-and-sharing tools available for doing that.
A big advantage is…
* That you can grab newspaper articles accessed via ProQuest and similar closed services, which Instapaper would not be able to log on to. Any HTML you can see in your browser can be grabbed, because the browser is where it gets grabbed from.