Here are my ten steps to switch to the DuckDuckGo search engine in Firefox, and have it work reasonably well across a PC desktop widescreen. In my view DuckDuckGo’s indexing and relevancy ranking is now ready for a serious test by power searchers. The image search relevancy, for instance, is arguably better than Google Images can offer.

1. In Firefox, switch your ‘home’ search-engine to https://duckduckgo.com/ in Tools | Options | General | Home Page.
There appear to be no useful URL modifiers you can append to this URL, for instance &show=15 to only show 15 results.
2. Look inside the little “three bars” icon in the top-right of your new DuckDuckGo search-engine page. Here you’ll find a variety of visual and feature settings that you can change. Changes can be either saved locally or anonymously to the Cloud. I assume you run AdBlock or similar and won’t need to turn off adverts, though DuckDuckGo kindly lets you turn ads off if you want to.
3. Note that DuckDuckGo’s Settings pages have several tabs, one of which is Appearance. This lets you change fonts and font size, link colours and more. If you just want search results to look a little more Google-y in that respect there’s also a very handy “DuckDuckGo Modifier” UserScript for Greasemonkey that will handle that for you. I like this simple addon a lot, and it will ease the transition greatly for many Google users.
4. You can also pick a base colour theme for the DuckDuckGo home and results pages, and then modify this theme by changing Background Colour using a Hex value from a simple colour-picker widget.
5. Power searchers who have learned to instantly sight-read an URL will want to turn on “Result Full URLs” and “Show the Result URL line above the snippet text”. Unfortunately longer URL paths are truncated.
You may also want to turn off the distracting tiny “Site Icons”, and allow URLs to be copied to the clipboard “as is” rather than in an obfuscated form.
6. Now install a multiple column layout for your search results. “DuckDuckGo – Multi-Columns” is a maintained GreaseMonkey UserScript and also a theme for the Stylish add-on, that will do this for you. Basically it does for DuckDuckGo search-engine results what GoogleMonkeyR does for Google Search results in Firefox.
Picture: Multi-column results, unwanted results hidden, customised colors.
Sadly you can’t limit DuckDuckGo to showing only 15 results, as you can with Google, which means some scrolling with this setup. Though you can turn off Autoscroll in DuckDuckGo’s settings, which helps a bit. But it’s still not ideal, for a widescreen desktop user who wants as little scrolling as possible.
Installing this “DuckDuckGo – Multi-Columns” add-on as a Greasemonkey UserScript is probably best, since then you can then easily edit certain features in the script. For instance, you can turn off the distracting “DuckDuckGo – Multi-Columns” results-numbering. To do this, find the scripts’ code-block that starts…
"/* (new3) RESULTS - COUNTER */"
… and change the colour and background colour codes to match your theme background, thus effectively making the numbers invisible…
" color: orange ! important;",
" background: yellow ! important;",
You will probably also want to change the awful bright red colour that the script uses to highlight your search keywords (when they appear in search result text snippets). To do that find the scripts’ code-block that starts…
"/* (new2) - RESULTS HIGHLIGHTING - ",
… and then change the colour name “tomato” to something less garish…
" color: tomato !important;",
7. Note that the excellent “Google Hit Hider” UserScript add-on for Firefox also works by default with DuckDuckGo. It seamlessly blanks results from URLs you’ve added to your personal list of unwanted domains.
You will probably want to choose to have this add-on’s “Block” button set to appear only when a search result is in a mouseover state, as it’s one less visual distraction for the speedy searcher.
8. Useful search modifiers that work for Google also work for DuckDuckGo…
-keyword these must be the last words in the search, to work.
“specific phrase“
“the ethics of *“ will wildcard a word in a phrase.
filetype:pdf or simply f: will find only PDF files.
intitle:keyword or simply t: only results with this keyword in the link.
sort:date or simply s:d Gives “sort by date”. This gives a simple re-sort of results to show only the most recently indexed results. My guess is that using s:d only brings results from a ‘recently indexed’ sub-set, and that any ‘recently indexed’ tag is jettisoned by DuckDuckGo once spam and adult content is cleaned and the clean results are passed over into the main index.
site:imdb.com Note that you can leave out the www. bit (unlike Google, which expects it).
-site:wikipedia.org No Wikipedia results!
site:imdb.com,rottentomatoes.com Search multiple domains in one go. It would be more useful if a user could somehow pin their custom chain of such URLs to the search box. But I guess you can set it up as a Bookmark on your Bookmarks Toolbar in Firefox.
-site:imdb.com,rottentomatoes.com,wikipedia.org Show no results from any of these sites.
region:uk Limit results to a national domain. This is also embodied in a very handy pop-out visual side-widget with nation flags, titled “Region”.
Most of these search modifiers can be combined, but it seems that sort:date only works if it is the final item in the search box.
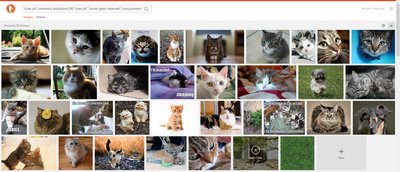
9. DuckDuckGo’s excellent Image Search has no Creative Commons filter. But CC can be approximated by adding keywords e.g.: Commons Attribution -Noncommercial. This actually seems to work very well, though you will of course need to check for the license and not take things for granted.
10. DuckDuckGo’s !bang feature sound like a pointless gimmick at first, but you soon start to realise the power of the !bang. !a will pass your search directly over onto Amazon, and !yt to YouTube and without going through those sites’ respective start pages. !gsc does the same for Google Scholar and !gb for Google Books. There are many more.
The UserScript add-on DuckDuckMenu provides a more familiar “top menu of links” way of using the !bang system. It’s also customisable.
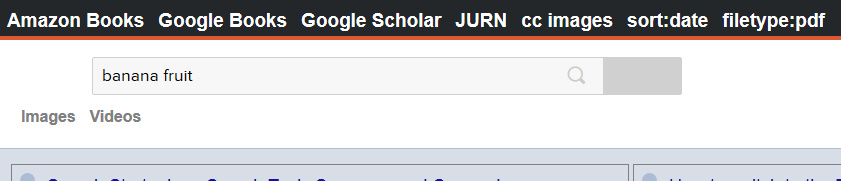
Below are the correctly formatted links for setting up some academic services on this menu. The inserted {searchTerms} section of the URL copies in the already searched search terms that are currently sitting in your DuckDuckGo search box.
Google Search (turn off the stupid AutoSuggest, force Verbatim, and return 15 results for use with three column results layouts such as GoogleMonkeyR):
https://www.google.com/search?q={searchTerms}&tbo=1&num=15&complete=0&tbs=li:1
Google Books:
https://www.google.com/search?q={searchTerms}&tbm=bks
JURN:
https://jurn.link/#gsc.tab=0&gsc.q={searchTerms}&gsc.sort=
Google Scholar UK:
https://scholar.google.co.uk/scholar?hl=en&q={searchTerms}
Amazon Books UK (books only):
https://www.amazon.co.uk/s/ref=sr_nr_i_0?fst=as%3Aoff&rh=k%3A{searchTerms}%2Ci%3Astripbooks
You can also add a handy no-typing way to instantly re-sort your search by date on DuckDuckGo itself:
Re-sort my DuckDuckGo search by sort:date:
https://duckduckgo.com/?q={searchTerms}+sort%3Adate
Add a filetype:pdf link to the menu:
https://duckduckgo.com/?q={searchTerms}+filetype%3Apdf
And an approximate Creative Commons image search can be had by using the link:
https://duckduckgo.com/?q={searchTerms}+commons+attribution+-noncommercial&iax=1&ia=images
Keep in mind that the latter link won’t pick up Flickr’s CC pictures, since Flickr obfuscates the CC licence behind a blanket phrase. For Flickr search it’s probably best to use search.creativecommons.org.
DuckDuckGo appears to have no Current News search function worth talking about (it’s sort of in there, but is very flaky about when it chooses to appear and is obviously not ready for prime-time). But !gn will pass your search through to Google News and !bnews to Bing News.
It seems you can’t yet create something like a BIG!bang that would search across a large collection of 100s or 1000s of specific URLs (like a Google CSE does) and/or RSS feeds, and thus approximate your own custom News search ability.