
JURN is a unique search tool, helping you to find free academic articles and books. JURN harnesses all the power of Google, but focusses your search through a hand-crafted and curated index. Established in 2009 to comprehensively cover the arts and humanities, in 2014 JURN expanded in scope. JURN now also covers selected university full-text repositories and many additional ejournals in science, biomedical, business and law. In 2015/6 JURN expanded again, adding over 600 ejournals on aspects of the natural world.
Last updated: November 2024.
Jump to a section…
How do I use JURN?
Who is JURN intended for?
Is there a browser addon?
What’s in the mix?
I see book chapters in the results?
I see an occasional repository item, such as a PhD thesis, in the results?
Is there a complete list of all journal titles indexed?
What’s not in the mix?
Does JURN run from your own curated set of URLs?
Does JURN have weak coverage of certain topics or areas?
Does JURN cover conference archives?
What are the general date ranges of the content in JURN?
Can JURN work with automatic citation capture software?
Does JURN have any Google Scholar like abilities?
JURN wants to return mostly English results when I search using words in another language. How do I fix this?
I’m pretty good at searching, why shouldn’t I just use the main Google?
Can’t I just use Google Scholar to access this material?
Can’t I just use the DOAJ to search open access journal articles?
Don’t Scopus / Web of Science / Summon index open access journal articles?
But my library discovery service claims to index open access journal articles?
I have free access to JSTOR. Isn’t that better for finding articles?
I import a PDF into my Mendeley PDF reference manager, and it searches Google? Isn’t that as good as JURN?
I keep being told to use Unpaywall to find open access content?
Is this just another hasty CSE search-engine, built in three hours and then forgotten?
Will I see adverts when using JURN?
How do you filter out the clutter that surrounds a journal’s core content?
What about link-rot and spam?
What about all the predatory open access journals?
What does ‘JURN’ stand for?
Who made your front-page banner graphic?
Can I submit my journal title or subject repository?
Could JURN become an independent search-engine, with its own crawler?
Why do this? Who does this?
![]()
How do I use JURN? You use it just like Google. But testing JURN with one or two words won’t get you very far. Better results will come from using the usual Google search modifiers such as the intitle: modifier, or putting phrases in “inverted commas”. So JURN works best for the typical academic user who has an adequate grasp of the better ways to search Google, and who also has some idea of the exact search terms they need to use. JURN also tends to loves specifics. For example, a unsophisticated search for…
Gender Studies Shakespeare
…will only obtain an interesting set of very broad and jumbled-up search results. A more sophisticated search will return much more specific and useful results, such as…
intitle:”The Tempest” Miranda gender
Here’s a quick primer on some of the ways to search JURN…
“your phrase” — Search for a phrase.
–keyword — Show no results containing this keyword.
intitle:keyword — Only results with this word in the link title.
“the ethics of *” — Accept any wildcard word inside a phrase.
ext:pdf — useful if you are sure you only want PDFs. It also picks up indirect re-directs which Google ‘knows’ go to PDFs (such as the re-directs Open Journal System journals use).
site:www.goodsite.com — Search only results from this site.
-site:www.badsite.com — Show no results from this site. Remember the www. bit.
This last search modifier is useful if you are overrun with results from mega-sites when doing science searches. For example…
intitle:banana cultivation -site:www.ncbi.nlm.nih.gov
Note that a JURN search query will also look for words with similar meanings or spellings, unless you force a ‘verbatim’ search. For example, if you do a search for…
conservation of tracing paper
… then the search will be for trace, as well as tracing. If this feature is not useful to you then you can turn it off by simply using quote marks, thus…
“conservation of” “tracing” “paper”
What about ‘known title’ searches, rather than using keywords? Note that a search for very long journal article titles, placed in quote marks, may not always give results in JURN. For instance: “Enhancement of adventitious root differentiation and growth” will give a result, at the journal Vitis : Journal of Grapevine Research. But a fuller selection from the same article title, “Enhancement of adventitious root differentiation and growth of in vitro grapevine shoots”, will not be found in JURN. This usually happens because for speed Google Search is usually searching against bundles of previous search result pages, not against some central database with carefully polished metadata. Sometimes a ‘&’ in the title will be interpreted as a problem, for instance the article title “Plugged in: Identifying Open (& Subscribed) Access” will only return a full set of results with the shorter “Plugged in: Identifying Open” fragment from the start of the title.
All this means that you should keep article title fragments short, and copy them from the start of the article title. This point should be kept especially in mind by researchers seeking to compare JURN with others search services by using “known title” searches.
(Warning: some Web browsers automatically try to make live links from anything that looks like a Web link. In that case the above links will read http:// when they should just read www.)
* independent scholars and researchers
* students and teachers in developing nations
* students enrolled on free MOOC online courses
* recent university graduates
* unemployed or retired lecturers
* knowledge professionals outside of academia
* business owners and leaders
* public policy makers and planners
* journalists and editors
* bloggers and Wikipedians
* public intellectuals and ‘think tanks’
* evidence-based campaigners
* amateur historians and biographers
* teachers of students aged under 18
* advanced and ambitious students, age 14-18
* home schoolers and grassroots educators
* hourly-paid university lecturers, who may lack paywall access during holiday breaks or may have to wait many weeks for library admin to get them access passwords.
* university lecturers and students, seeking a strong search tool for open access content
Yes, with a UserScript addon you can integrate JURN right into Google Search, or add it to the DuckDuckGo interface. For instructions and links, see my blog post: JURN ‘in a UserScript’.
You can also add JURN to your Bookmarks bar as an Itty.bitty link. An Itty.bitty link is the Web page, encapsulated within the bookmark itself.
![]()
What’s in the mix? JURN’s unique strength is coverage of open access arts and humanities journals, something which has been highly curated and refined over a period of many years. See the JURN Directory for a list of all the English-language arts and humanities titles indexed, although please note that this list does not cover the many journals included in JURN that are published in other languages. In March 2014 JURN became a multidisciplinary index for open access articles, following the completion of a large initial intake of open journals on ecology, nature, palaeontology, business, law, economics and the practical healthcare aspects of biomedical. Also added were several open science full text aggregators, selected full-text university repositories, and all known full-text subject repositories. In early 2015 many armed forces / self-defence journals were added, alongside more titles in business and law. In September 2015 mapping science journals were included, along with many of the more important open geology / geophysics ejournals. By November 2015 the very large intake of eco/nature ejournals had been completed, pushing the total of such English-language journals indexed to over 500. An intake of the smaller geology and geophysics journals is scheduled for late 2016.
![]()
I see book chapters in the results? JURN includes a number of URLs that bring in PDF “free-sample chapters” offered from reputable scholarly book publishers. Publisher file-naming conventions vary, but JURN has managed to exclude most book indexes, standalone tables of contents and dictionaries.
![]()
I see an occasional repository item, such as a PhD thesis, in the results? From March 2014 JURN started including some of the newer and more discriminating global repository search services, such as CORE, that focus overwhelmingly on adding records with full-text links. Since that time, fulltext at a selected range of the world’s larger general and subject-specific repositories has also been directly indexed in JURN. At November 2015 the following are included in JURN, with fulltext targeting…
* All known major specialist subject repositories.
* The likes of Zenodo, ArXiv, PubMed, NIH and similar.
* Selected major open data and map repositories (record pages only).
* All UK and Irish repositories (both directly and via CORE).
* All Australian and New Zealand repositories (directly).
* All larger U.S. and Canadian repositories (directly).
* Selected robust African repositories in Kenya, Tanzania, South Africa.
* Central and Latin American repositories via their regional aggregator.
* Repositories in many other nations, via their national or regional aggregators.
* BePress Digital Commons topic pages.
* Many minor repositories (because departmental journals often store their PDFs there).
* Archive.org but on a highly selective basis (early JSTOR, university presses).
* Official national services, the military, and major transnational bodies.
The addition of repositories to JURN is being monitored for distortion of the journal search results, but so far it doesn’t seem to cause problems. Google Search, in which JURN is a Custom Search, generally tends to favour journal articles and ranks their links a little higher.
JURN also has a side-project in beta, GRAFT, which searches across all the world’s academic repositories. At June 2017 GRAFT indexes around 1,400 more repositories than the similar and older OpenDOAR services does.
![]()
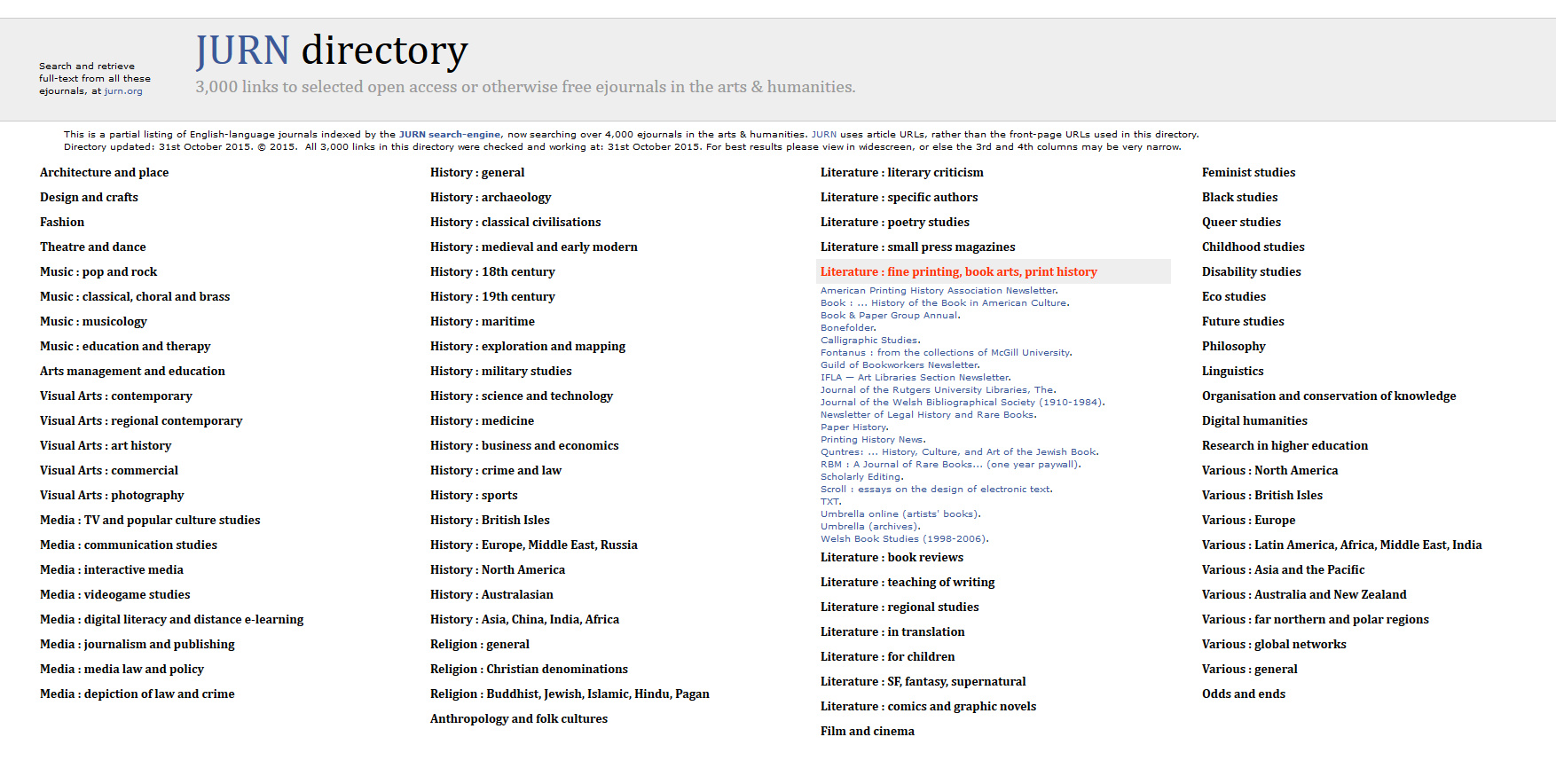
Is there a complete list of all journal titles indexed? There used to be a PDF A-Z list of all arts and humanities titles indexed. This was complete on 2nd April 2011, but it is now no longer updated. A fully maintained and organised list of the arts and humanities titles is available as a live linked directory. As of September 2015 JURN also offers a maintained A-Z list of 800 ecology/nature related titles included in JURN. Note that both of these maintained lists only cover ejournals published in English.
Jan Szczepanski’s List of Open Access Journals is also very useful, especially for finding titles published in languages other than English and which are unlikely to be on the DOAJ.
![]()
What’s not in the mix? General commercial ejournal websites — such as those of Blackwell, Elsevier, Oxford, Intellect, and similar — are of course not indexed, unless JURN is able to target only their open access articles. The Flash-heavy websites used by a few fine arts / art photography / architecture journals have a hard time being indexed by Google, even if they’re being indexed by JURN. Some e-journals “hide” the actual full-text articles from Google in various ways (by using hard image-scans of journal pages, database-driven dynamic numerical URLs, javascript obfuscation, or through the use of robot.txt files) and so are hard to discover via search.
![]()
Is JURN run only from your own curated set of URLs? Yes, JURN only shows a search result if the result’s URL path is in the JURN index. JURN is not the more general and ‘scatter-gun’ type of CSE, which can be summed up as: “all of Google Search + your chosen domains mixed in and boosted in the results ranking”.
![]()
Does JURN have weak coverage of certain topics or areas? No attempt has been made to include educational studies journals, other than a few selected titles in Higher Education research. Social studies and psychology are likewise very poorly indexed by JURN at the journal level. Open scholarly journals in fashion and beauty are very rare and so hardly indexed, although fashion related articles will of course be found from journals in cultural studies, business, history and suchlike. For journals published in languages other than English, JURN often relies on indexing via a single-point national aggregator of open content (such services exist for French, Spanish, Catalan, Japanese and a few other languages). Italian arts and humanities journals lack such an aggregator, but since they are of such high quality a special effort has been made to include nearly all of them in JURN.
![]()
Does JURN cover conference archives? Fulltext conference archives are usually avoided, because their URLs are so unstable. Their PDFs are usually “here today, gone or moved within 18 months”.
![]()
What are the general date ranges of the content in JURN? The material in JURN was mostly published in the age of the mass market Internet, meaning after 1994, with the bulk of indexed articles being published after 2005. The largest gaps probably lie in the 1923-1993 period, partly due to antiquated copyright laws and partly to gaps in academic digitisation programmes and sometimes the simple lack of paper copies to scan. Even when digitised, older journals tend to be published online in Google-unfriendly ways — jumbled indiscriminately into university repositories on undifferentiated URLs, presented only as hard page-scans with no OCR and little contextual HTML, or presented as individual page scans via clunky special viewers requiring special plugins. Such awkward online presentations can make it difficult for JURN to index older journals. However, in March 2014 JURN was able to experimentally add the JSTOR pre-1923 articles collection to the index, via their mirror on Archive.org.
![]()
Can JURN work with automatic citation capture software? JURN has been built using a Google Custom Search platform — so half the time you’ll be lucky to see the actual article title in the search results link. This is one of JURN’s weak points. You’ll often have to do some hand-building of references for JURN-sourced articles, and back-tracking to find out what journal it came from — since many open journals don’t bother to embed the journal title in the article PDF file. However, you might want to test Paperpile for use with JURN.
![]()
Does JURN have any Google Scholar like abilities? JURN doesn’t have Google Scholar style “relevance ranking”, “related articles”, “number of times cited”, “recent articles”, or the ability to sort by author or title of a journal, etc. JURN is very far from what a librarian would call “optimised” in its presentation of results. But this can actually be a good thing, since it reduces herd behaviour and exposes your topic search to some useful serendipity. Note that, from May 2012, you can re-sort the JURN search results by date — this feature works best in combination with the use of the current year date as an additional search keyword.
![]()
I’m a linguist or country specialist. JURN wants to return mostly English results when I search using words in another language. How do I fix this? JURN does ‘auto-translate + add synonyms’ when a user searches using non-English keywords, while also auto-detecting your home nation. For instance, if you search from the UK for the single word…
مقارنة (Arabic, meaning: comparison, comparative)
… then the UK user sees search results containing مقارنة OR comparison OR comparative, with English language results predominating. Search instead for “مقارنة” (in inverted commas) and the majority of the search results are in Arabic.
This automatic nation-detection feature makes results more useful, for most people. But it may present a problem for linguists or country specialists who regularly search JURN, or for those who are part of a diaspora living outside their home nation. One solution might be to spoof your IP address via the free VPN in the Opera Web browser, the turning on of which allows you to pretend to be in another nation. Browsec and other services provides similar free ad-free VPNs.
Note also that JURN is unable to handle «the continental European style of quote marks».
![]()
I’m pretty good at searching, why shouldn’t I just use the main Google? Note that using JURN serves to remove unwanted results. None of which can be removed from the main Google search results by even the most sophisticated search veteran. For instance, material such as: Powerpoint files converted to PDF; old academic resumes; commercial journal abstracts for paywall articles; educational course documents; university marketing materials and departmental web pages; course descriptions and reading lists; plain academic repository records with no link to any full-text; articles in predatory open access journals; articles by creationists and anti-vaccination crazies; old promotional flyers for conferences and calls-for-papers; posts to blogs and mailing-list archives; slides from half-baked undergraduate seminar presentations; the millions of “K-12” lesson plans for school children; spam/virus sites which appear to create a PDF and Web page for every book with an ISBN, and so on.
![]()
Can’t I just use Google Scholar to access this material? Overwhelmingly, no. Online presentation and web archiving of open ejournals in JURN’s core area of the arts and humanities tends to be haphazard and inconsistent. This is especially so with journals from learned societies and university departments. Most of the ejournals indexed by JURN don’t even use something as basic as RSS feeds (only 212 out of the JURN Directory’s 3,000 English-language titles use RSS), and few actually embed their journal title and issue details in the PDF. Very few seem to offer OAI-PMH. The resulting difficulties in automatic and accurate harvesting of metadata may be one of the reasons why open ejournals in the arts and humanities are very poorly indexed by Google Scholar, a service that requires automated collection methods. For instance, a 2011 study of Scholar by art historians found that Scholar was indexing only half of the DOAJ’s 30 art history titles.
![]()
Can’t I just use the DOAJ to search open access journal articles? The DOAJ is a fine directory for academics who seek journals to publish in, but in terms of full-text search it consistently does very poorly on the JURN group tests. The DOAJ’s full-text article coverage is actually quite limited in the arts and humanities. By my calculations at December 2013 the DOAJ appeared to present article abstract records, those leading to full text, from around 470 open ejournals in English in the arts and humanities (inc. linguistics, philosophy, anthropology and ethnography). At November 2015 the DOAJ had grown to “10,779 Journals”, 5,554 of which were flagged as publishing only in English. Of those English-only titles, 710 also have arts/humanities or ‘general works’ subject classifications. By comparison, JURN indexes over 4,500 arts and humanities titles — with around 3,000 of those being in English.
Also keep in mind that it is DOAJ policy to remove a journal if it has been inactive in the past year, whereas JURN is happy to index a moribund or resting journal just so long as it keeps its archives online.
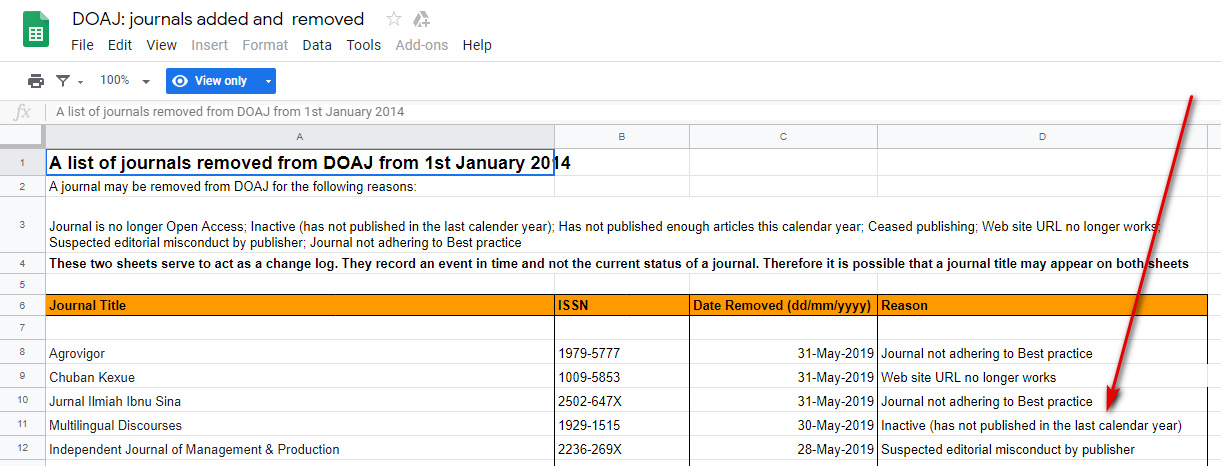{kind=link}
Nor does the DOAJ always have full coverage of a field, for various reasons. For instance, a 2015 study of the indexing of cartography and mapping science journals found 47 such titles being published as open access, but only eight of those were in the DOAJ. The same can be true of country coverage — in terms of Spanish journals, at November 2016 there were found to be only “507 Spanish journals indexed in DOAJ”. In comparison, JURN has excellent and wide coverage of Spanish and Portuguese journals.
![]()
Don’t Scopus / Web of Science / Primo / Summon index open access journal articles? These are good commercial resources, if you have free institutional access to them. But they struggle to index the full range of open access full-text content. One study of the indexing of open access journals in Communication Studies found only 32% coverage in the big subscription journal databases. And a 2014 chart appears to show that only 11% of open access content produced by the Netherlands is currently indexed in Web of Science.
Scopus and Web of Science services appear to index less than 1,000 arts and humanities journal titles (commercial and open access together) in English, and in general their open access journal coverage is very far from complete. For instance, at June 2015 the Scopus journal titles spreadsheet has 1,634 titles published in English from the USA, Canada, UK and the Commonwealth countries and included in its Arts and Humanities category. When these titles are sorted by the new Open Access tag in Scopus, the figure is reduced to just 60 titles (including such arty titles as Canadian Journal of Speech-Language Pathology, Journal of Biomedical Discovery and Collaboration and Asian Social Science). Figures from November 2015 show that Web of Science covers just 72 open access titles in the arts and humanities.
Summon’s coverage of open access is said to be a little better for the arts and humanities, but it depends heavily on third-party aggregators and university repositories at a time when the dire state of repository metadata means that harvesting full-text article or thesis content struggles to rise above 30%.
The poor quality of metadata, and also the occasional mis-use of repositories as general university Web storage, means that many libraries will turn off access to cross-repository search, even when it comes to them via reputable commercial databases like Primo. Such wholesale removals of all repository content may also remove the many small open access journals, which happen to be hosted by university repositories…
“21% of the respondents [members of the PRIMO-DISCUSS-L list] concede they rarely or never activate resources from the ‘Institutional Repositories’ section in PCI [Primo Central Index, the IR section of which contains 350k OA scholary articles at 2015]” — François Renaville, “Open Access and Discovery Tools” chapter in the forthcoming book Exploring Discovery: The Front Door to a Library’s Licensed and Digitized Content.
![]()
But my university library discovery tool claims it indexes open access content?
A university library discovery tool may well be useful, if you are a student or academic who has free institutional access. And if your institution’s library has staff dedicated to adding and cleaning open access intakes. But hardly any libraries can afford to have such dedicated staff. Libraries instead rely on bulk inputs such as the open access full-text links included in the SFX service, which is often part of a university library’s suite of discovery tools. A 2014 study of SFX’s main ‘free’ MFE database found broken links running at far above 20%, even when very conservatively measured. A further study concluded that no amount of ongoing maintenance by librarians would cure this problem, since… “The effort spent maintaining our link resolution knowledge base does not make a long-term difference in the link resolution quality.”
The DOAJ (Directory of Open Access Journals) databases are apparently not much better in this respect…
“It’s an irony that I find discovery services generally have much poorer coverage of Open Access than Google Scholar. … Most discovery services have indexed DOAJ, but many libraries experience such a bad linking experience they just turn it off” — Aaron Tay, Library Analytics Manager, Singapore Management University, July 2015.
By comparison, a JURN user should find almost no dead links.
![]()
I have free access to JSTOR. Isn’t that better for finding articles? JSTOR is a good resource for the humanities, if you have access behind their paywall (note that JSTOR does offer some partial free access to independent scholars). But articles typically only appear in JSTOR some years after publication, whereas the bulk of open access current journals indexed by JURN publish their articles freely and immediately. Also, there is generally little overlap in the titles indexed between JURN and JSTOR (other than pre-1923) so by using JURN you are effectively searching a different range of journals.
![]()
When I import a PDF to my Mendeley PDF reference manager, it searches Google and tries to find full-text for the paper’s references? Isn’t that as good as JURN?
That’s a useful time-saver, but one could do that manually, and possibly with more precision and fewer unnecessary never-to-be-read papers being downloaded. According to Elsevier’s Help page Mendeley searches Google Scholar, but not the open Web via Google as JURN does. Google Search and Google Scholar are run from completely separate databases and servers, and they use different harvesters. Which means you’ll miss a lot if you’re only reliant on Google Scholar for getting full-text, as my group tests have shown. The results of my group tests receive support from library science papers such as “Scholarly Journals in Museum Studies”, a 2016 study of indexing coverage on Museum Studies journals, which found seven major open access titles on the topic but only four of those were indexed on Google Scholar.
![]()
I keep being told to use Unpaywall, the Web browser addon, to find open access papers?
Unpaywall only searches papers that have been assigned a DOI, a common practice in the realm of science and medicine. But the majority of arts & humanities journals do not use DOIs. For instance: Matti Rissanen, “Colloquial and comic elements in ‘The Man in the Moon'”, Neuphilologische Mitteilungen 81. No DOI exists anywhere for this article.
A peer-reviewed test survey found that Unpaywall could only find a mere 1.1% of a large set of arts and humanities open access papers (see: “Evaluating Zotero, SHERPA/RoMEO, and Unpaywall in an Institutional Repository Workflow”, Journal of Electronic Resources Librarianship, 2019). DOIs may anyway be extremely unreliable. For instance, in 2020 the Los Alamos Labs team found that, of a 10,000 random sample… “consistently across request methods, more than half of our DOIs fail to successfully resolve to a target resource” — “On the Persistence of Persistent Identifiers of the Scholarly Web”, presented in March 2020 at the CNI Spring 2020 Project Briefings. Further, DOI articles are also poorly preserved. In a 2024 sampling of 7.4m article with DOIs, 27.64% were found to be “missing” and “seemingly unpreserved”.
![]()
Is this just another hasty CSE search-engine, built in three hours and then forgotten?
No. It’s had years of intensive work put into it. JURN was launched on 3rd Feb 2009. The building and refining of the core site-index made JURN usable by early March 2009. By early April 2009 JURN came out of alpha. By late May 2009 JURN was indexing over 2,800 titles, the additional titles overwhelmingly found by my own Google searches. By early June 2009 JURN was essentially complete and out of beta, and I announced it as such on the blog. By November 2009 JURN was indexing over 3,400 titles, the total again boosted by my own intensive searching. By February 2011 JURN indexed 4,101 titles. This had risen to over 4,600 titles by December 2013. The indexing URL set is actively checked and maintained.
![]()
Will I see adverts when using JURN?
No. JURN is non-profit and ad-free. Some independent journals are however starting to use free services such as WordPress to host their articles, and these may show advertising. If that bothers you then simply install an ad-blocker in your Web browser, such as Adblock Plus.
![]()
How do you filter out the clutter that surrounds a journal’s core content? JURN doesn’t index journal home pages, unless it can’t be avoided. Instead JURN uniquely uses the actual Google-visible article URL, rather than the home page URL. Every effort is made to exclude paywall pages, in journals which are only partly free. For an idea of how JURN tries to index only the free full text articles, see here.
![]()
What about link-rot and spam? A regular Linkbot-based ‘404 – not found’ hunt is undertaken, based on the links Directory, to help treat the inevitable link-rot. Home-page URLs that are flagged as broken or moved are investigated and relocated, usually leading to the discovery of a moved content URL. JURN also uses special software to check if the article-level URLs are still being indexed and displayed in Google search-results. Spam-magnets, such as defunct journal blogs, can be blocked using the CSE Exclude tool or by tweaking the original URL so as to only target the articles. Google also plays its part, by constantly indexing and weeding dead links from its databases. For these reasons you should find almost no dead links in JURN, despite its vast size and scope.
![]()
What about the faux or predatory open access journals, whose publishers are only interested in the publishing fee? JURN’s curator is well aware of such dodgy practices, and rigorously excludes such journals. So far as is known no publishers on Beall’s List of Predatory Publishers or Journals are directly indexed in JURN. I subscribe by RSS to all the blogs on the sidebar (see right), some of which are devoted to tracking predatory and dubious open access publishers, and I take note of new accusations and evidence. I also monitor the DOAJ’s list of removed ejournals.
![]()
What does ‘JURN’ stand for? JURN’s curator comes from a youthful background in publishing science-fiction ‘zines, and as such has always liked the fannish idea that an acronym-headed fanzine would have a different explanation of its initials for each issue. This practice was later taken up by some lesbigay publications — see the back-issues list of the queer literary zine RFD as an example. So feel free to make ‘JURN’ stand for anything, on any given day. Journal Usury Recovery Net? Jolly Urbane Reading Node? Jumped Up Rattle o’ Nuthin? Just Usable for Regular Nerds?
![]()
Who made your front-page banner graphic? Thanks to the Blender Foundation for the Creative Commons matte painting used in the background. I colour shifted it in Photoshop, and the font used for the JURN lettering was ‘FogLighten 04’.
{kind=link}
![]()
Can I submit my journal title or subject repository? If you don’t think your arts and humanities ejournal is likely to appear in the DOAJ or EZB, then you’re welcome to leave a comment and your journal’s URL as a posting on this blog. Please keep in mind that JURN’s curator tracks various news sources, and your journal may already be indexed. Tracked are:
* the DOAJ new titles feed;
* New in the EZB (selectively and cautiously, due to the low level of quality control);
* the DOAJ removed journals list.
Please check that your journal is not already listed in the JURN Directory or in JURN’s openECO A-Z…
Please also note that JURN is not currently accepting individual journal submissions from outside of the arts and humanities or ecology/nature, but welcomes hearing about aggregation services for open content in fields where there is likely to be extensive lay / public / business interest — such as space flight, biomedical, geology and geography.
![]()
Could JURN become an independent search-engine, with its own crawler? Yes, and there are already public-domain Web crawls such as Common Crawl which might be leveraged to help lighten the harvesting load.
![]()
Why do this? JURN was created and is curated and maintained by David Haden, a British teacher with twelve years of experience — including nine years teaching at the School of Theoretical and Historical Studies, Birmingham City University. I also worked for JISC’s Intute project for several years, where I was tasked with finding and cataloguing open access journals. After Intute closed, a casualty of the recession, I did further paid cataloguing work for JISC. I’ve since spent seven years building JURN, because I believe that free knowledge needs to be made easily find-able. The Web is so huge now that useful material can easily become lost in the immensity. So I used Google, the best and fastest tool for online discovery, to build a simple direct interface to aid in the finding of full-text open journal articles and book chapters. Now JURN can be used by anyone in the world who has Web access, for free. I think that giving pre-focused and curated access to free high-quality knowledge is a worthy task, one worth putting some time into.
![]()
JURN does not index medical journals, except under very special circumstances.
Dear Sir,
I request the inclusion of this journal in JURN: Revista Cientifica MG.Biota, please.
Many thanks, Marcia. Your journal is now indexed in JURN at the article-page level. To test this, search for the recent article title “Formigas removedoras de sementes apresentam potencial”.
I’m rather surprised that the Brazilian Scielo aggregator doesn’t index a government ecology journal. I urge you to request that they do so, and also to consider requesting a DOAJ listing.
Pingback: JURN, Firefox 5 and HTTPS-Everywhere | News from JURN
Could you please add Coleção Estudos Cariocas to your list?
https://estudoscariocas.rio
The journal has just been migrated to OJS and is not yet ready to be added to DOAJ and Scielo (will wait a few months for the first post-OJS edition to be published). Nevertheless, we would like to start adding it to other engines and aggregators, since we have uploaded more than 100 articles from the last 20 years.
Thanks. Added, and I tested some article titles. But you are not yet showing up in results – this is seemingly because Google Search has not yet indexed the OJS. When Google indexes you, you’ll then be in JURN too. I strongly suggest you also get indexed by the various Spanish/Portuguese aggregators such as SciELO – Brasil.
Thank you. It is now indexed in Google Scholar as well! So I believe it now appears in JURN.
Would it be possible to index Philosophy and Global Affairs:
https://www.pdcnet.org/pga
Sadly, I got blocked by a Cloudflare captcha, on trying to access the current issue. I’m loath to send people to pages with such roadblocks.
Hi David, thanks for the tip on keeping the article title fragments short and copying them from the start. I used to copy-paste full titles from references and wonder why custom searches struggled. This makes so much sense now. Appreciate you keeping this index so clean and helpful for all these years!