Total refusal to visit a normal website.
This common Web browser problem is usually related to only a handful of sites and is incredibly difficult to troubleshoot, and for most people will be impossible to fix. I tried everything, and I know Windows and browsers inside-out. Nothing worked.
The ‘nuclear’ cure, which works with Opera and apparently other Chrome-based browsers, is then to simply add the following to your browser icon’s launch path. This path is found by right-clicking on the launch-icon and then looking in its Properties path. No more problems, if you add there…
-ignore-certificate-errors
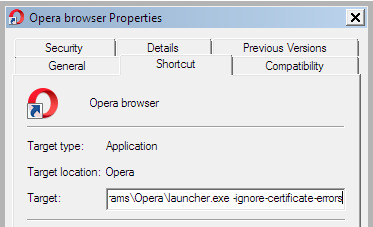
This needs to applied after the shortcut has been pinned to the TaskBar, not before.
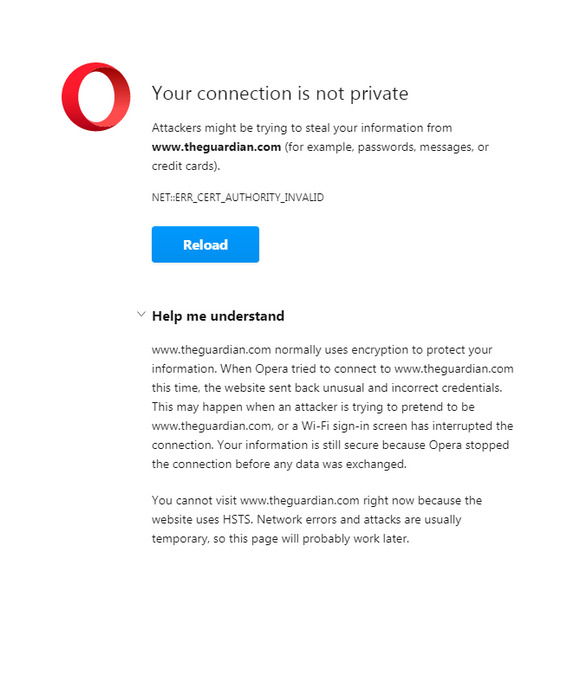
The site will now load fine. Tested and working with the Opera browser and theguardian .com
Obviously this will not be the same browser you use for Internet banking, PayPal etc. Or in such cases you will at least launch the same browser from another un-fixed launch icon.
The alternative is to switch from Chrome to the Pale Moon browser. Pale Moon, being based on Firefox, uses its own certificate store rather than relying on that of Windows. I don’t know of any way to have Chrome do the same.
Update, December 2023: this old post takes on a wider significance…
“Proposed EU legislation gives European governments the ability to conduct man-in-the-middle attacks against secured web communications (i.e. https). It would be illegal for browser makers to reject certificates compromised by governments.”