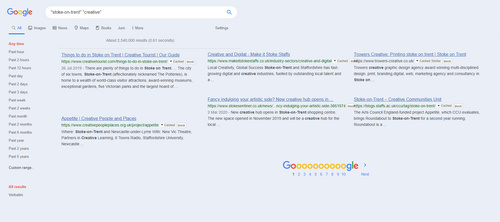
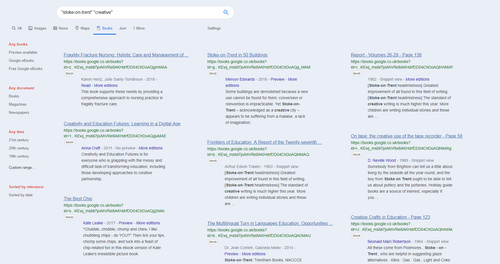
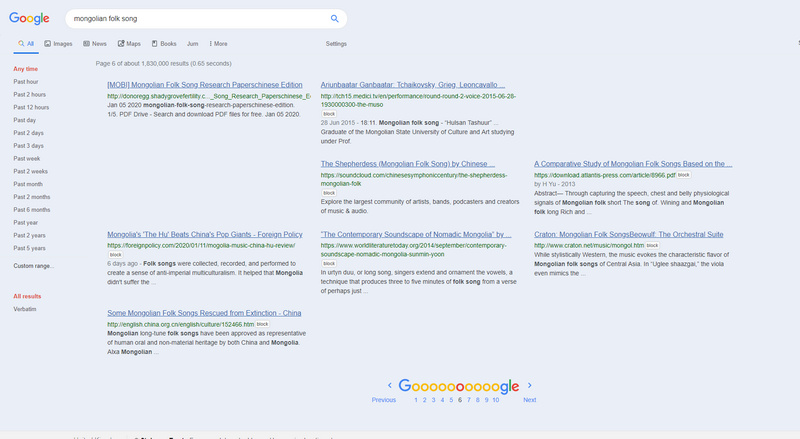
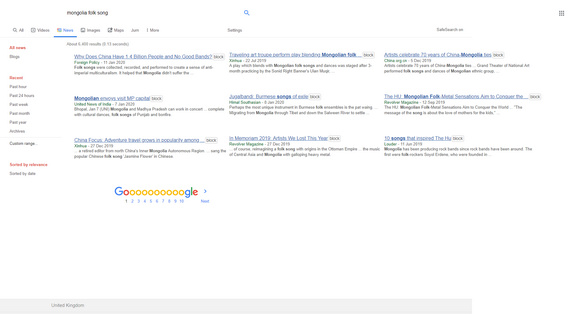
Following on from my testing of new scripts in recent days, here’s a basic summary list and quick-start on what you’ll need for three column search in Google in 2020. This follows the effective demise of the much-loved GoogleMonkeyR.
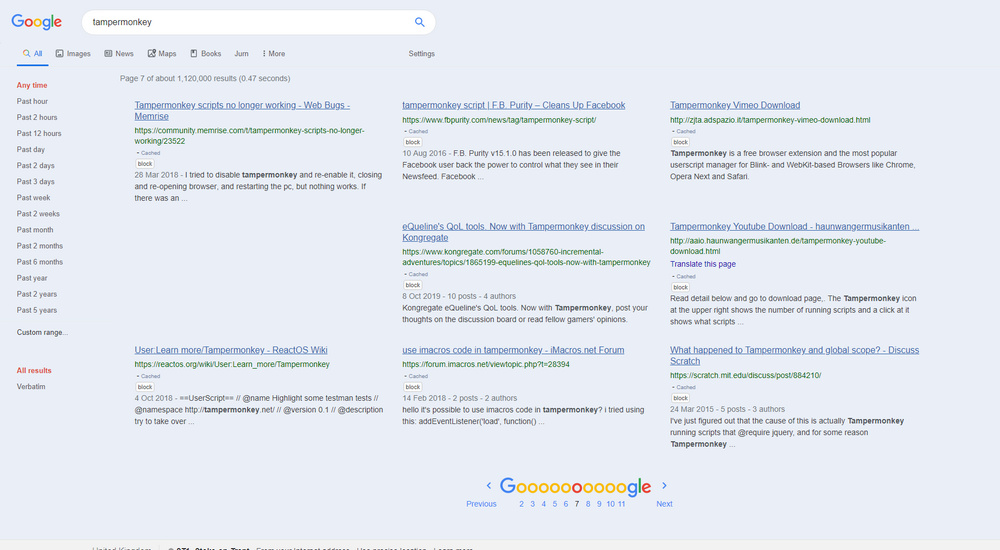
First you want a good Chrome-based browser. Opera for Desktop is in use here, at 1920px. Turn off addons and scripts likely to conflict with the new ones listed below.
I assume you already have auto-suggest etc turned off, when formulating search-queries at Google, and are using a widescreen desktop PC.
Core script-management and element-blocking addons:
1. Tampermonkey for installing and running UserScripts.
2. Stylus for installing and using UserStyles.
3. uBlock Origin for blocking, and knowledge of how to use its element picker and how to edit its “My Filters” list. (I suggest that you unsubscribe from the “Peter Lowe’s Ad and tracking server list” after install, due to over-reach. It’s found under Filter Lists | Multipurpose).
UserScripts and UserStyles:
1. Google search in several columns for Tampermonkey.
And then tell it to exclude Google Books, by adding the following lines to the top of the script…
// @exclude http*://xxx.google.*tbm=bks*
// @exclude http*://xxx.google.*.*tbm=bks*
… where xxx = www
You may want to tinker a little with the script’s column-width settings, in certain parts of the script, to better fit your widescreen monitor. If you plan to use Google Search Sidebar (see below) then install that before you start tinkering with these widths.
Update at end of March 2020: script broken by changes at Google Search. Temporary fix.
2. Then let the Stylish script Google Search in columns handle the three columns for Google Books results, having first set the script to three columns when you downloaded it. This script also appears to have the very useful effect of preventing the other UserScript columnising script from splitting an individual search-result across two columns, with a bit awkwardly placed in each column. The two scripts seems to be able to co-exist on Google Search, News etc.
Cosmetic:
1. Re-order the top menu in Google, and remove links to “Shopping”, “Flights” etc, if unwanted.
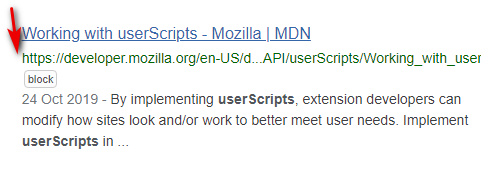
2. Google Search restore URLs (undo breadcrumbs) + Old Google Search. Together these two place a full URL path, under the link title in your results, like it’s always been. Another script noted below will make the URL path green, like it should be.
3. Google Search Sidebar and its expansion Google Search Various Ranges. This also works with News, and “two weeks” seems a good recent time-point at which the Googlebot has cleared a lot of the robo-spam from Search but results are still fresh.
4. Google Hit Hider by Domain (Search Filter / Block Sites). Dynamically and automatically remove results according to a user’s own URL blocking list. But it leaves a space in the results page, so that the layout is not ruined and the user knows something was removed. Blocking is done by a little “Block” button placed next to each result.
5. Fix Google Images a bit with Google Search – Always Show Image Size.
6. Google Search – Visible Cached + Similar links. Add back the “Cached” link (which still works). Then hack the script to make the Cache links small and also colour-matched to your theme — simply add “font-size: 10px;” and a basic color fix in the /* Actual Link */ section of the script; and then add this wholly new section and tweak its colour chip…
/* li background */
.ab_dropdown {
background: #eaeff7!important;
}
7. Google Search – Classic Links. I’ve adapted mine for use in combination with the above and a preferred coloured background, and it looks like this…
/*** Basic fix of the main links to appear less shouty ***/
#search a h3, #search a.l {
text-decoration: underline !important;
font-size: 16px !important;
color: #3666aa;
/*** Since URLs paths are visible in results, make them green ***/
}
cite.iUh30.bc.iUh30 {
color: darkgreen;
}
Blocking tweaks:
You’ll then need to use the Picker tool in UBlock Origin as you search…
…to block all the spammy ‘suggestions’ panels, massive ‘helper’ panels, nags and suchlike that will appear from time-to-time on your page to clutter up your Google Search.
The following will also be useful for en-masse blocking of images in search results in News and Books, using UBlock. Paste them into your UBlock Origin “My Filters” list, save it, then reload Google.
! Block any page-panel containing the keyword X - here the word is 'videos'
google.com##g-section-with-header:has-text(/Videos/)
! Block all Google News Thumbnails
google.*##[id^="news-thumbnail"]
google.*##[alt^="Story image"]
google.*##[class^="gs_md_"]
www.google.*##*.sYpfDb
www.google.*##*.QyR1Ze
! Remove remaining image-block padding spaces on the News results
! and block the image favicons on results while we're at it
google.com##a.top.NQHJEb.dfhHve
google.com##.xA33Gc
! Block all Google Books cover thumbnails en-masse
google.com##*.th
The Google Books cover-thumbnail space cannot be removed, only the thumbnail images that sit on top of that space. The empty space left behind seems to be ineradicable.
That’s it. Enjoy your newly columnar, cleaned and tweaked Google search experience.