The JURN blog’s sidebar is now linking to both versions of “Beall’s List” of predatory and questionable publishers. The currently updated list, and the old list available via Archive.org.

18 Sunday Mar 2018
Posted in My general observations, Spotted in the news
The JURN blog’s sidebar is now linking to both versions of “Beall’s List” of predatory and questionable publishers. The currently updated list, and the old list available via Archive.org.
16 Friday Mar 2018
Posted in Spotted in the news
The digitized medieval manuscript: open access resources, a big up-to-date survey, annotated and linked.

09 Friday Mar 2018
Posted in JURN tips and tricks
Facebook to RSS – FetchRSS. I tested it, it works, and with Groups as well. Though your Facebook Group needs to be Public, not Private. $5 a month for a 25-item RSS feed, though it seems the feed has no ‘re-sort by date posted’ functionality.
05 Monday Mar 2018
Posted in JURN tips and tricks
I found the excellent 123Apps Online Audio Converter, which extracts the audio from any online video. No sign-up needed. I fed it a Web link to a 6Gb MIT conference video. (Sadly that was the only option MIT offered, but not all users have i) superfast Internet, ii) the spare disk space, or iii) a video editor that can handle such a beast of a file without crashing).
The 123Apps service downloaded the video onto its servers speedily (about 5 mins). It then offered me a .MP3 of the audio from the 6Gb video, with conversion to .MP3 taking another minute or so. The .MP3 then downloaded with no hassle, at a comfortable 495Mb containing a day’s conference audio at a good quality.
Similar services appear to place limits on the online video size they can digest, such as 500Mb or 150Mb. Which means it’s useful to know that 123Apps can handle very large video files, and that it works very smoothly.
05 Monday Mar 2018
Posted in Spotted in the news
To be continued… The Australian Newspaper Fiction Database is excavating a wealth of fiction from the scans of pages of Australian newspapers. Interesting, but I must say that it has a search interface that only a librarian could love, and my search for “Rosaleen Norton” or Rosaleen Norton on the author field both threw up fatal database-error messages. An alternative search in the “Publication Author” field of the item grid, for Norton, worked but had no results.
As a wider test of what’s been digitised in Australia I went instead to Trove – Newspapers – Advanced Search and searched for “Rosaleen Norton”. She was a notorious occult/horror artist subject to an art censorship court trial in the early 1950s, and who as a girl had three H.P. Lovecraft-style macabre stories published in the popular Smith’s Weekly newspaper (Sydney, 1919 to 1950). She may possibly have been one of Lovecraft’s late postal correspondents, evidenced by some strong internal stylistic evidence and her story “The Painted Horror” strongly resembling Lovecraft’s lost juvenile tale “The Picture” (1907). He was known to send this story out at this time, for teenage authors to work over and learn from.
Excellent results were had with Trove. The accounts of the controversy and her trial show up in the 1950s. And two of her stories were available as scans and with original illustrations to boot. Though sadly the often-fragile UK-Australia Internet connection died before I could search for her third story, or see if there were other stories as yet unfound.


01 Thursday Mar 2018
Posted in Academic search, Spotted in the news
I see that I missed the publication of a new book about Google Search. Harnessing the Power of Google: What Every Researcher Should Know was released in summer 2017, when I wasn’t paying much attention to news. It’s a short primer of 150 pages and the contents list looks very encouraging. These contents seem to chime with a blog review and an Amazon review, which both suggest the book is aimed at… “librarians who will be working with researchers”. Implying researchers of the type who will expect to be working with expert Google users rather than Google-phobics.

It’s possible to peer inside the book via Google Books. Sadly this shows that the book doesn’t mention the rich possibilities of Google Custom Search, as a keyword search of the text shows no results for either “custom search” or “CSE”.

It appears that the book has yet to receive any open/public reviews from librarians. But the business researcher blog Infonista has a polished and informative review.
27 Tuesday Feb 2018
Posted in Academic search
Access to Freely Available Journal Articles: Gold, Green, and Rogue Open Access across the Disciplines (2016 conference presentation script/summary, published 2017)…
“We randomly selected 300 articles that were indexed in Scopus and published in 2015. A hundred of them are from the arts and humanities, and a hundred of them are from the social sciences, and a hundred are from the life sciences, and all of them, again, randomly selected.”
These 300 appear to have been a random mix of paywall and OA and were then searched for on Google, Google Scholar, Researchgate, and Sci-Hub. The researchers were simply looking for free public copies of the articles, wherever they could be found.
The methodology used is slightly fuzzily explained…
“We just did a title search. We didn’t do anything further than the title search”.
Fuzzy, because a Google “full-title” known-title search “as a phrase” is not the safest way to go about such a test. Due to the way Google Search works, ideally one would want to search on the first 50 characters of the title instead of on the entirety of a long academic article-title.
Also, Scopus is poor at indexing Open Access, only managing 29.18% coverage of the DOAJ Open Access titles even in 2017. And the Scopus spreadsheet, now sortable by OA status, indicates Scopus has very poor coverage of OA arts and humanities titles. So 100 arts and humanities articles from Scopus is not a great starting point, even if suitably randomised. The sample will likely skew heavily toward paywall articles.
Anyway, even with these limitations the results for public full-text free-access were somewhat interesting. From left to right, just for the 100 Arts & Humanities articles: Google Scholar, Google Search, Researchgate, and Sci-Hub (prior to its recent problems)…
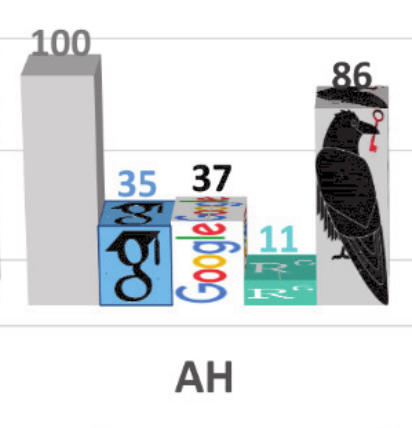
Sci-Hub was known to have severe problems accessing things like recent Project MUSE articles, so perhaps glitches like that prevented an even higher result than 86%.
26 Monday Feb 2018
Posted in Ecology additions, New titles added to JURN
Bay Nature (conservation of habitats and wildlife in the San Francisco Bay Area)
22 Thursday Feb 2018
Posted in New titles added to JURN
20 Tuesday Feb 2018
Posted in Spotted in the news
An apparently new Delhi Declaration on Open Access…
“The Directory of Open Access Journals (DOAJ) lists only 200 out of the 20,000+ journals being published from India.”
Yes, the DOAJ part of the statement is correct. I downloaded the DOAJ .CSV, sorted by Country. There are indeed currently 201 journals in the DOAJ with a country identifier “India”.
At November 2013 the DOAJ figure for “India” was 598, so presumably a great many Indian-published OA titles went during ‘the great purging’ at DOAJ.
But the Declaration’s “20,000+ journals being published from India” can’t all be Open Access. Presumably by “20,000+” the authors are talking about all journals, of all types. Thus it might have been better and fairer to DOAJ if the Declaration had been rather more precise, by comparing the 200 DOAJ-listed OA journals to the total number of known non-predatory OA journals published from India.
Update:
An India and Pakistan study of “open access journals indexed by Scopus up to Oct 2017” found that the “major share of journals are from India, which contributes 593 Journals in which only 218 (37%) journals are currently active” (Akhoon and Ganaie, “Status of Open Access: Across Borders”, 2018).