Hurrah, there is freeware to get a free WordPress site to Word as a .DOCX file, and thence to an ebook. Only the one, and hardly known to search-engines, but it’s for Windows and it works. WordPress2Doc comes from Germany and was last updated by the author, Raffael Herrmann, in December 2017. The source code for WordPress2Doc is on Github.
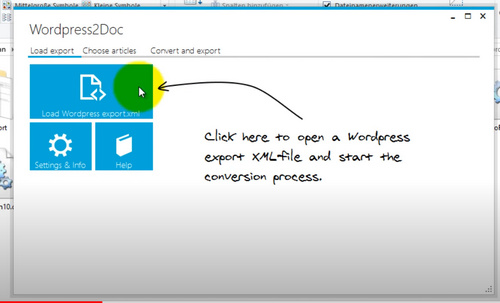
It has some nice features…
* Select only certain posts from your exported .XML feed.
* There’s a post preview, over in a side-panel.
* Images are called and embedded (so long as the source WordPress blog is public, presumably).
* Images are correctly sized for the page (if you just copy-paste straight into Word from your blog post, they’re not).
* The blog’s pages are also exported and can be selected, as well as the posts.
* You can also save straight to a PDF, as well as Word.
* Can save each post as named Word .DOCX file.
There’s a PDF Help guide in the download, but there’s also a good Help video at YouTube. But it’s very simple and easy to use. Once you have your Word file, it’s then relatively easy to save to an ebook.
If you’re still using the old WordPress UI, then you may want my guide to how to export your site as an .XML export. Because using the old interface won’t get you a viable export. Incidentally, it seems WordPress are now chunking the .XML export of large blogs. I had two .XMLs in the backup .ZIP, for my medium-sized test blog.
The only bother for an ebook maker will be re-ordering into themed sections or chapters without a whole lot of tedious select-copy-paste, and WordPress2Doc can’t help even partly with that as it lacks tag-support and list re-ordering before saving the .DOCX file. The best way to tackle the problem is probably to export in themed batches, one per intended chapter or section, though that would entail making ten passes of what might be 4,000 posts. Which is not ideal. But it looks to me like WordPress2Doc works best with smaller blogs anyway.
But note that WordPress can export posts to .XML by category, at least. Also, WordPress2Doc can save multiple selected posts as ‘one file per-post’. You could then sort into chapter folders by dragging and dropping, and then use a Word joiner to join them together.
Update: I don’t like the over-compression of images with this method, and some of the text formatting is also lost. I’m coming to the conclusion that one would ideally tag posts with the category “ebook-ch1”, “ebook-ch2” etc in the blog itself, then view that category, then copy-paste the page(s) into (Libre Office) LibreOffice Writer. Unlike Word, this retains formatting, including italics and indented quotes, and also retains picture quality. In almost all cases the pictures are scaled correctly to the page width, which they’re not when using Word to do the same thing. Small pictures such as icons are not scaled. Word cannot do this, even with a macro.
This all assumes, however, that you still have a live blog with its CSS, and not just the .XML export files.