I’m amazed that there’s no easy way to skip across precise multiple sections of an audio file, when playing back in a laptop/desktop audio player. And to then have one’s choices of sections ‘stick’.
For example, I have a 56 minute audio track, downloaded as an .MP3. I am going to listen to this repeatedly, on a loop, and on playback I wish to always skip minutes 0:00 to 9:30, and then 15:30 to 26:00. The player should save my choices and then ‘always skip these sections, whenever I play this file’ locally.
As far as I can see the only options for doing this on a Windows desktop are…
a) actual editing of the audio file in a good audio editor such as Audacity or similar. But an MP3 can take an age to load and then to save out, when dealing with a 50-60 minute track. At a half-hour to laboriously load and process each one, that’s a whole day wasted if you have an album or long audiobook to to process. And if you’re not savvy about export settings, you can also compromise audio quality on export. The clumsy may also risk overwriting the original file.
b) it can be done via a hand-coded workaround that makes a VLC Player playlist. Not ideal, but it seems to be the best current solution and VLC is safe and well supported. It’s relatively quick and wholly non-destructive of the original files.
The simplest form of use for this is…
1. First preview your audio file and make a note of the various ‘in’ and ‘out’ points, giving you a list of just the segments you want played. For example…
PLAY 09:31 – 15:29
PLAY 26:01 – 56:30
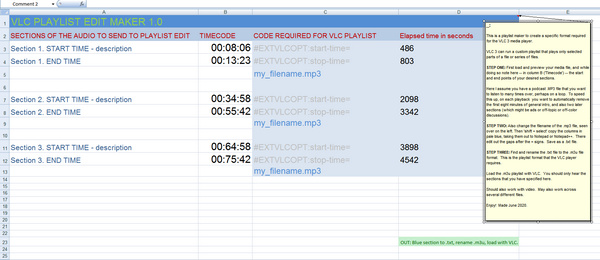
2. Then open Windows Notepad and copy the starter template…
#EXTVLCOPT:start-time=1550
#EXTVLCOPT:stop-time= 2611
Acquired Ears.mp3
#EXTVLCOPT:start-time=2890
#EXTVLCOPT:stop-time=3803
Acquired Ears.mp3
The numbers here are the time in seconds elapsed since the start of the audio file. start-time and stop-time should be self-explanatory.
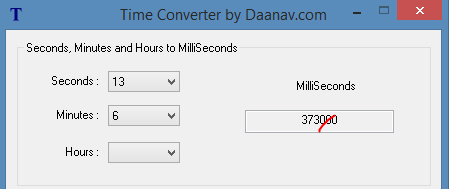
3. Now use the Time Code to Seconds Web page to translate your own noted times to seconds, seconds being the only measure that VLC Player can handle. Most crude online converters only deal in pure seconds. The one linked above can cope with proper audio-player values, such as 26:33. There appears to be no way to do this inside VLC.* A local desktop option for this is the simple Windows freeware Time Converter 1.0. It gives you milliseconds and to get seconds from that you just lop off three zeros…
Update: I made a better solution, a VLC Playlist Edit Maker 1.0 Excel spreadsheet.
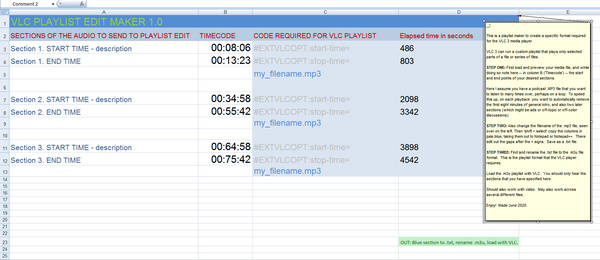
Obviously you also paste in your own file name(s). Blank spaces in the filename don’t phase VLC player.
As you can see you can have multiple sections of the file listed for playback. It appears that each selection/section/segment must follow after the last such, though it might be possible to skip back and forth across the file. It also appears you can also skip between audio files and generally create quite a complex playback mix. Try such things and see. But for the purposes of this tutorial, all that’s needed is a stepped sequence of playback across one file.
4. Once done, you save it out as a .txt file. Then rename this file so it’s a .m3u playlist. The playlist must then be located in the same folder as the audio file(s).
VLC can loop the playback of such a playlist. Video subtitles are said to play nicely with the ‘playlist edited’ playback.
This saved .m3u playlist only seems to work as intended in VLC Player, not in AIMP or other players that also know about .m3u playlists.
Apparently this also works for video, thus potentially easily enabling the lightweight distribution of ‘edited’ or ‘abridged’ versions of video/audio files, along with the actual files themselves. This relieves a potential editor of the need to wrestle with actual editing and re-encoding of the raw file, in a video editor or audio editor. Which, as anyone who has tried it knows, is a pain is the arts.
Now… if only VLC could also fix its broken “Continue playback” feature, which has never worked for me on a desktop across multiple versions — despite all the right switches being set in Preferences | Interface. The only solution I know of is to specifically call the target playlist from the Windows shortcut, by editing it thus…
“C:\Program Files\VideoLAN\VLC\vlc.exe” C:\Users\Music\playlist.m3u
Then, clicking on the resulting shortcut to launch VLC also automatically launches the target playlist. If it’s a playlist configured as above, it will play as it should and loop as normal. It still won’t automatically start at the point you left off listening when you closed VLC, but it’s better than nothing. AIMP, in contrast, handles such things perfectly and with no problem or setup at all.
Anyway, one can see the uses of such special playlists, for instance for reducing fiddliness when using video in the classroom. Or for offering just the ‘edited highlights’ of a long three-hour podcast without actually going to the trouble of editing it in Audacity. Or for creating a quick ‘cleaned’ version of media for viewing with young children. There may be some paid ‘subscriber value’ in offering such ‘playist edits’ to Patreon patrons etc, or as a ‘mailing-list special feature’.
Indeed, there’s potential for a desktop freeware / Web site combo which makes the above process as easy as possible, and then allows the social sharing of ‘playlist edit’ .m3u files, in much the same way as subtitles are already shared. Perhaps the ability to upload the user’s final edit would be contingent on summarising what was in the excluded bits, and having labelled the file correctly (e.g. ‘this section of the music appears to feature a yodelling camel’, and ‘music edit, to skip unwanted singing’).
* VLC Player also has the addons ‘Jump to Time’ (doesn’t appear to show seconds in any useful way for this purpose), and ‘Time 3.2’ (impenetrable interface, and even when finally wrestled into supposedly working it shows no seconds count anywhere in the UI). There appears to be no other ways of showing elapsed seconds / milliseconds inside VLC 3 via a plugin, though “Crtl + T” will grab it during playback. One final option is the VLC 4.0.0 alpha (most people are on the 3.0.1 stable version). This has SMPTE timestamps, SMPTE being industry-standard timecodes apparently including milliseconds. But the 4.0 .MSI and .EXE refused to install for me, and the .ZIP install just gave a black UI. You may have better luck with it in future.