Sometimes you get a PDF where the page is “squished”, as seen here…

Bad, some dunderhead saved the pages with slightly wrong proportions and didn’t notice.

Good, as it should be.
It can also happen when ebooks files are being bulk converted to .PDF files. It’s often especially noticeable where there is artwork with faces. The slightly “squished” or “stretched” result is locked in a PDF file and is difficult to change. It’s no use trying PDF tools that only scale a page proportionally, or simply crop the page, or will re-print from U.S. Letter size to UK A4 size etc. Because you only need to change each page along one dimension, not along both.
There are three or four online tools for fixing this in a PDF, though that’s not much help if you have a 200Mb PDF and a very slow upload speed, or are offline. Or have 50 such files to process. Or if your business has a mission-sensitive document you’d rather not sent to Whereizitagin. The full paid Adobe Acrobat can also do the repair though in a clunky way, from Adobe Acrobat DC (2015, not to be confused with Adobe Reader) onward, via fiddling around with Preflight and following a convoluted recipe.
Are there any fast Windows desktop options? I found and tested three working possibilities, one free.
1. The free and trusty Irfanview can open PDFs (with the free Ghostscript and free plugins pack installed). This combo can together open and page through PDFs. Irfanview can even resize the first page in an unconstrained way, so you can work out what your re-size dimensions need to be. Sadly it can’t then flow this resizing over to all subsequent pages. Instead it can at least automatically save out all the pages as .PNGs or .JPGs, then you’d open their output folder and batch resize them with Irfanview. Then you’d re-compile them back to a .PDF file, or zip them into into a Comic Book .CBZ file.
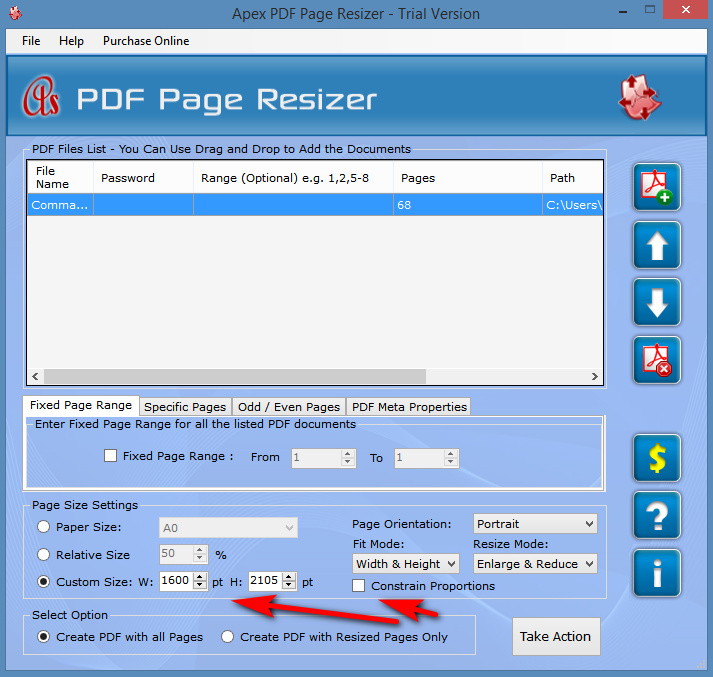
2. Apex PDF Page Resizer did the job easily and perfectly, although it’s expensive at $20 via FastSpring. Over-priced, for a one-trick-pony that won’t be used too often. There’s a 30-day trial with only a light watermark.
3. Advanced PDF Tools at $38. Twice the price it should be, but it does the job after a quick bit of fiddling with the settings. As you can see here, you scale the Page Content by a % and then pad in pt’s to accommodate the added width or height. It’s a bit more hit-and-miss than Apex.
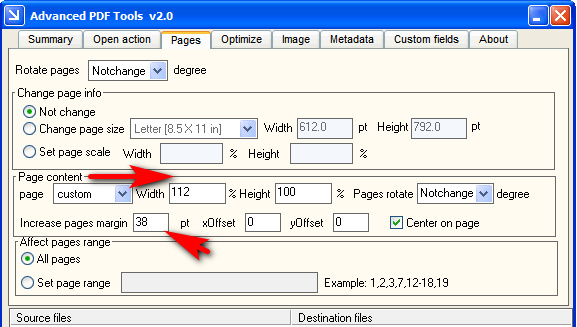
As you can see, you’re getting many more features than Apex PDF Page Resizer. But the very fast output speed and exactly the same file-size in output suggests it is working in much the same way as Apex, probably via a .NET Windows GUI that gives a pipe into several key Ghostscript switches.
In both, the settings are then run across all pages, and a new repaired .PDF is swiftly saved out. It strikes me that such a relatively slight change could be one way of detecting a leaker in an organisation. Give each person a .PDF copy with very slightly widened or lengthened pages, such that each imperceptibly changed .PDF is unique to one person.
I looked hard but could not find anything with a GUI for Windows that hooked into Ghostscript’s resizing and scaling switches in the same way as the above two, but for free. pdfScale: Bash Script to Scale and Resize PDFs using Ghostscript came closest (see the scripts at the end) and may interest some.
If you just want to crop pages to a user-defined rectangle, including instances where you have several columns on the same page, the free Briss is well recommended.
(If you have a related problem, a PDF that shows the curved pages of a book as photographed from above with a hand-held camera, see my recent How to auto-correct curved book pages post)