
I’m pleased to present a free ‘ISSN harvester’ for Excel 2007 or higher.
What you need: You have a long list of home-page URLs, one per line. You want a small snippet of data captured from each HTML page. The target data is not in any kind of repeating HTML table or tag, and could be anywhere on each page.
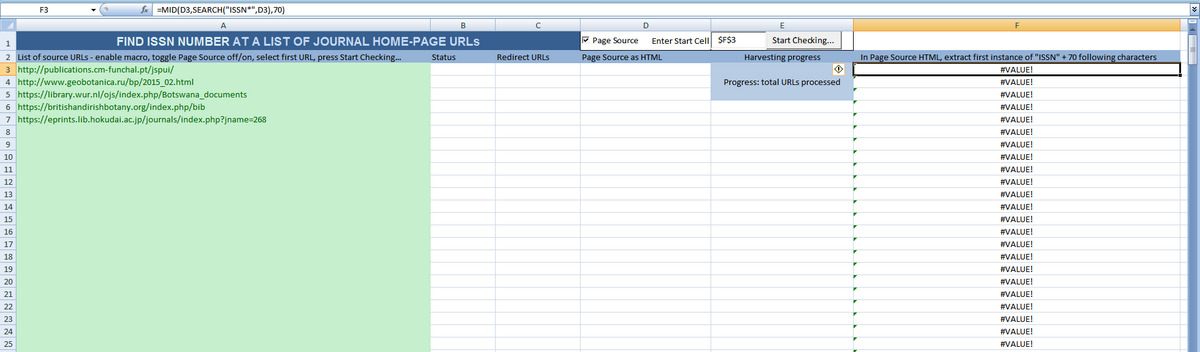
Usage: A long list of home-page URLs is pasted into the first column. The sheet then checks each URL in turn, and also extracts their HTML source into an adjacent cell. A formula in the end column then looks at the captured HTML and extracts the first instance of “ISSN” and any 70 following characters. Where no result is found, the formula leaves a general label as a placeholder.
Download: ISSN-and-data-checker-working.xlsm
Works in Windows and Excel 2007. May require the user to have Internet Explorer installed. Tested and working fine on an 800+ URL list. Each URL just captures the loaded page, not the entire website.
It should be adaptable to capture any snippet of data, just vary and replace the formula. Theoretically, you could also add extra columns to capture other data from the same HTML, such as “i s s n” or “eISSN”.
Credit: This is derived and expanded from the free “Bulk URL status checker in Excel sheet”, which checked a list of home-page URLs for 404s, and also rather usefully extracted each page of HTML to a cell while it was about it. I would have had no idea how to set up that ‘HTML per cell’ bit, without his working example. That spreadsheet was kindly shared on the TechTweaks blog by ‘Conscience’ in April 2017. Here it has been adapted by myself to also extract data.
Pingback: Some free tools to extract data from fetched HTML | News from JURN