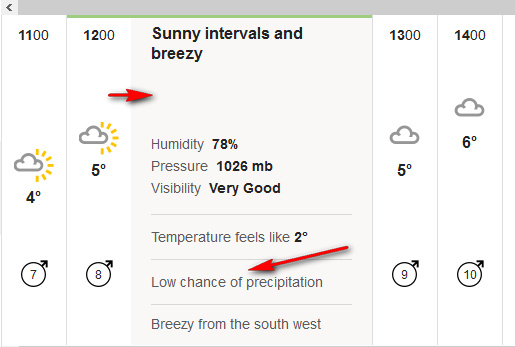
In Autumn 2017 Google announced that Google Search would ignore the country domain of its service, and instead serve you national results based on what Google thinks your geographic location is…
“the choice of country service will no longer be indicated by domain. Instead, by default, you’ll be served the country service that corresponds to your location.”
Here’s my quickstart on some of the nation-specific research options which can route around this. You either need to:
i) use the likes of DuckDuckGo and add national URL Parameters to the end of your bookmarked URL: e.g. Hungary. Top results are not great in that instance, with BBC, Wikipedia and Guardian cruft, but they quickly become relevant as you scroll down. Adding site:hu helps a lot, at the cost of knocking out local grassroots blogs on WordPress and Hungarian .org and .com sites etc.
DuckDuckGo is now actually better than Google, in my opinion, for picture research. Though you will have to home-brew a Creative Commons filter within your search terms.
ii) Go to Google’s Advanced Search settings and (for now) you can request that Google Search “narrow your results” by nation. Clunky, but it may prove useful. I imagine there must be a browser plugin that allows this setting to be swiftly switched across various nations.
iii) use a VPN proxy in your Web browser. The Opera web browser has a free and sturdy VPN built in, but all you can do with it these days is to select broad regions rather than nations (as used to be the case). Adequate for things like quickly getting past region-blocking on public domain resources at Hathi, etc, but not that useful if you just want to research ceramics in Morocco.
iv) use a few free VPN such as Browsec. This offers three or four free national VPN nodes, of a limited access duration (10 minutes or so before it becomes unresponsive). Again, useful for researchers wanting to access region-locked Hathi books or YouTube videos etc. Such freebie VPNs also offer an enticingly big list of other national nodes for paid users…
v) The TOR browser. Google’s new move potentially leaves sensitive ‘business researcher traffic’ open to being snooped on and tracked by hostile/piratic nations, who may either clandestinely run and/or can tap into VPN traffic. As such, smaller business — especially those in a larger supply-chain but without security-savvy IT departments — might also look into the anonymous TOR browser’s capabilities before doing intensive country research. It’s my understanding that some TOR exit nodes can be geolocated to nations, while others appear to be free of geolocation, and apparently one can switch between these types and choose which nation the exit node is in.
So far as I’m aware, JURN has for some time now auto-detected your home nation and served results accordingly. Some types of user can route around this somewhat, by searching in a local alphabet and encasing words or phrases in quote marks (“مقارنة”) which in this case should mean the majority of search results are in Arabic.