Wrestling around trying to view and export Creative Commons .SWF files, without an Adobe Flash installation? The wholly freeware Windows Free Flash Decompiler can open even early-version Flash .SWF files and save to .PNG images with scaling. version12.0.1 is the installer Windows users need. (Link updated for new version of Free Flash Decompiler, January 2021. Works fine, post-Flash)
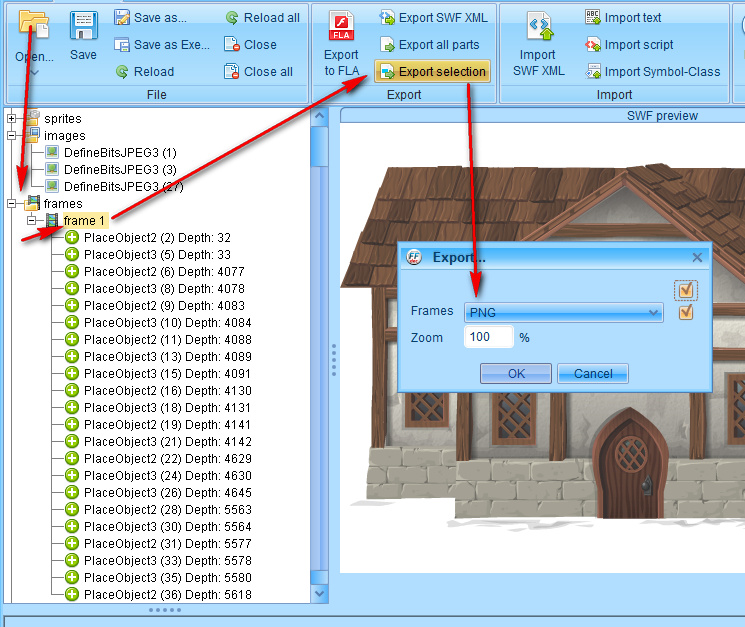
Useful where games have released their art assets under Creative Commons, such as the Odd Job Jack series. Especially if the .SWFs were output in Flash 5, which is very old now, but Free Flash Decompiler had no problem with the older assets.
The free Flash Decompiler was the only genuine freeware found, after hours of searching, which could open such Flash 5 .SWFs (be sure you’re trying to use it to open .SWFs and not .FLAs!). It only lacks a batch processing feature. It doesn’t seem to work with .SWF output from Poser 11, in terms of being able to display or save the render like the Internet Explorer browser can.
Paid options with batch are:
* reaConverter, which can read old SWFs and has batch, but has no option at all to scale up the PNG output, which makes it utterly useless. Update: the latest reaConverter 7.x has % scaling for saving .SWF files to .PNG format.
* SoThink SWF Decompiler, expensive at $80. It has a nice viewer and can read old .SWFs. But it has no .PNG output, only the .SVG vector format. However, this .SVG output can then be further batched with ConversionSVG which is a free 2008 front-end Windows GUI for the free Inkscape. Both ConversionSVG and Inkscape still work fine together. The only slight drawback is that ConversionSVG has no % upscale, so you may need to run it twice, once with 2400px on height and again on 2400px on width. Then manually go through and delete each mis-fire for the very long or very wide graphics. Also, note that not all the Flash gradients will make it to a .SVG file, either mangling or failing. Also, ConversionSVG seems to be a Java application, which is a potential security risk. If you do try it, it requires some juggling at first to switch it from French to English. But it works fine.
* VeryPDF Flash to Image Convertor, which is $20 and has batch, but its PNG output is very fuzzy and unusable at 3000px. It’s fine for making lots of little 400px preview PNGs, but not for anything larger.
Thus, a batch solution for those with 20,000 items to convert is: SoThink SWF Decompiler > batch export to .SVG > install Inkscape > install Java > install ConversionSVG for Inkscape > batch your .SVGs to .PNGs.
Of course, you could get all arcane and command-liney about it, hooking into ImageMagick or similar, but this post is for those who need Windows software with a GUI.
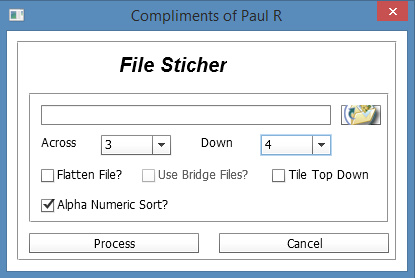
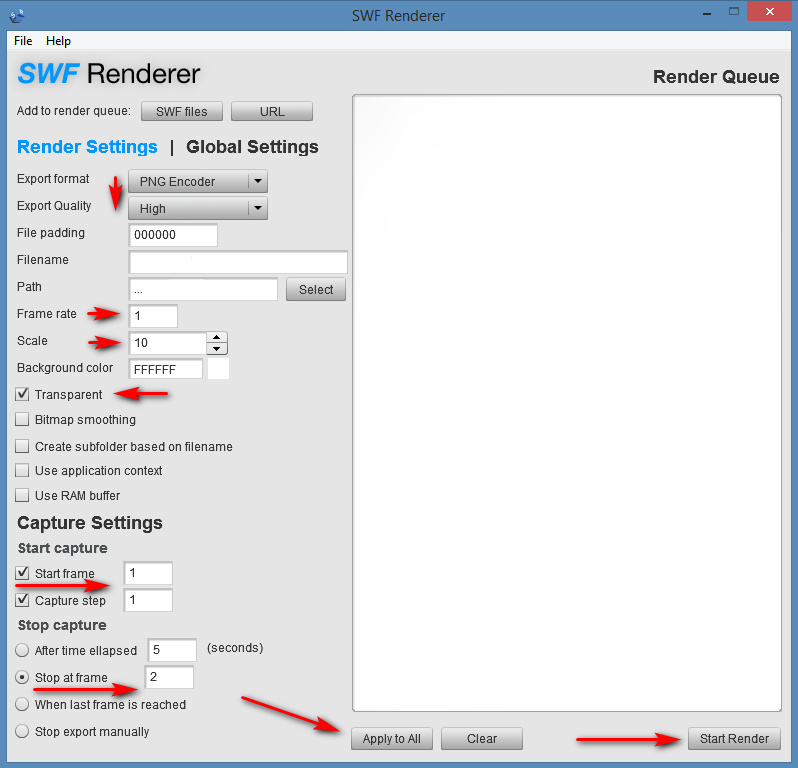
Update: No need for the .SVG intermediary, as I found the $15 Kurst’s SWF Renderer 2.0, which does batch SWF to PNG and has scaling and respects transparency. There’s a demo version, Windows or Mac. Works fine and fast, on Adobe AIR rather than Java. Below are the settings, for outputting a single frame from each .SWF file. Note that you can’t, as with the Free Flash Decompiler freeware above, choose which bit of the .SWF (shapes, frames etc) to output. SWF Renderer 2.0 is a frame renderer, not a shape decompiler.
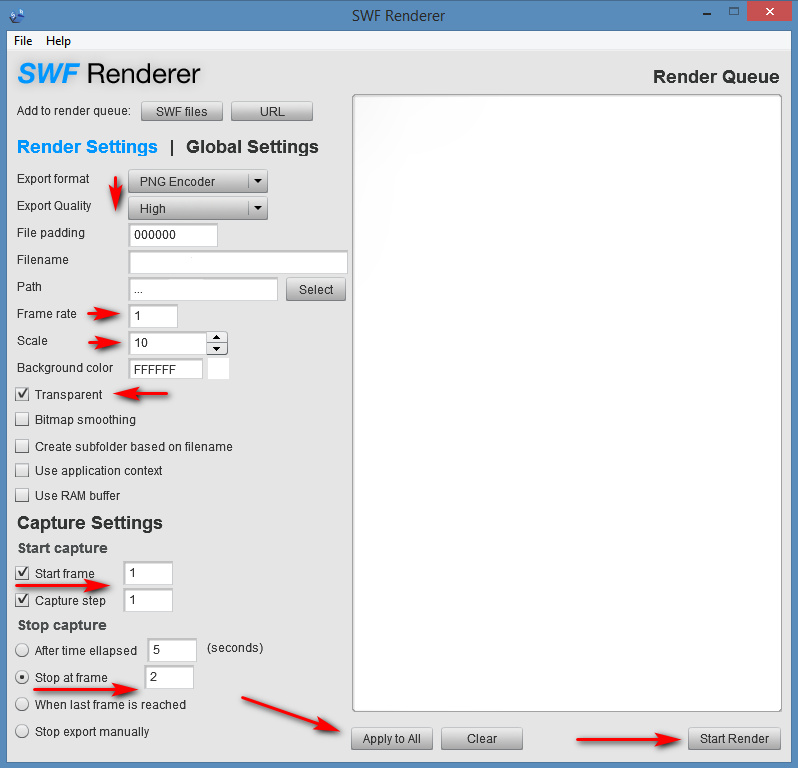
It’s best to chunk the load you give it, to around 100 at a time. You can’t just load in 28,000 SWFs and expect it to cope.
Update: reaConverter 7.x can now scale up and gives nice PNG output, albeit at a cost of $50. Needs to be scaled to 10000% to get anything big (4k+) out of it…
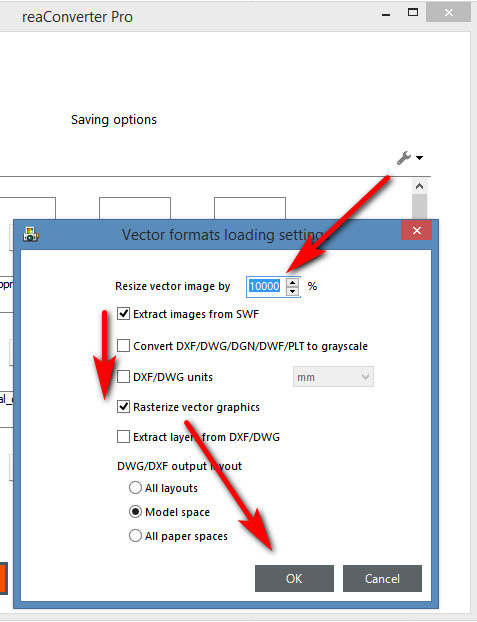
Regrettably it is not reliable at this scale, is very prone to crashes when handling folders with more than a dozen files. Also it often mis-handles transparency and clips renderings. The other viable software, on the other hand, could handle what Rea could not. With the only drawback being lack of batch in Free Flash Decompiler, and the 10x scaling limitation on Kurst’s SWF Renderer 2.0.
Update: After Adobe killed Flash in January 2021, the following results from testing:
* JPEXS Free Flash Decompiler – FINE, with previews, after an update to the latest version. Still no batch.
* Kurst’s SWF Renderer – FINE, no update needed. Still can’t export higher than 10x.
* SoThink SWF Decompiler – OK, no previews at all, but SVG image loads in Inkscape.
* reaConverter – FAIL on the latest 7.6 versions, on preview and render.
Thus, JPEXS and Kirst presumably have internal standalone Flash implementations. Testing reaConverter on a Windows 7 Xeon workstation reveals the cause of its apparently flakiness. When it hits an animated .SFW it feels the need, unlike the other software, to load and then render every frame. Rather than one frame. Naturally, this causes the SWF player module in the Java implementation to use way too much RAM and die. The Xeon Workstation has 24Gb of fast RAM, so it’s not a problem there.









{kind=link}