I’ve un-installed the Scriptsafe browser addon, which had been my Opera browser’s main script-blocker since I switched to Opera. A service, seemingly hardwired into this addon, has overstepped the line and caused the addon to become a nannying URL blocker rather than a simple script blocker. Specifically, it appears to have an agenda about which bona fide affiliate links it will and will not accept. One cannot even whitelist some of these perfectly genuine and useful URLs, as they are actively refused in the addon’s interface.
I suspect the problem is upstream, rather than with the maker of the addon. Since Scriptsafe includes by default…
block unwanted content (MVPS HOSTS, hpHOSTS (ad/tracking servers only), Peter Lowe’s HOSTS Project, MalwareDomainList.com, and DNS-BH – Malware Domain Blocklist are integrated!)
These lists are ‘hardwired’ into the addon… and are thus impossible to inspect or turn off, it appears.
Thus I went looking for an alternative. Naturally I took a look at the respected TOR browser — they use NoScript 10.2 by default. Well, if it’s good enough for the world’s best hardened browser then it’s good enough for me. I installed it, in the form of the Opera browser fork NoScript Suite Lite. That addon was simple to use and gave me no nonsense when I clicked on the links in question at my friend’s site. I was sent straight through to my intended destination, as used to be the case.
It’s obviously not Lowe’s list or MalwareDomainList which is causing Scriptsafe to be so nannying, in this instance. Because my uBlock Origin also uses that same blocklist. Therefore it must be one of the other lists that actively blacklists entire domains. I also considered uMatrix 1.3 extension from the makers of the leading adblocker uBlock Origin. Installing uMatrix and then comparing the blocklists suggests to me the hardwired inclusion of the DNS-BH list in Scriptsafe was causing my initial problem.
This sort of ‘The Browser Says NO’ attitude is why I moved from Firefox… which increasingly gave the user no choice about exactly what one let through from the Web. I, ‘the user’, should be the one who always ultimately gets to decide that.
Anyway, for those following my occasional browser tutorials and similar at JURN, I’d now recommend the easy NoScript Suite Lite and uBlock Origin as the core blocker duo for ordinary users of the Opera browser. But, in the end, I personally opted for the more sophisticated uMatrix as a fine-grained personal blocker (which is what I had mostly used Scriptsafe as).
So… advanced users may prefer the far more complex uMatrix 1.3 addon / extension rather than the simpler NoScript Suite Lite.
Basic initial configuration of uMatrix is to:
i) click on the tiny grey cog-wheel in the top-left corner | Host Files tab | there un-check any lists also used by uBlock Origin, so they’re not both trying to do the same thing at once. You may also want to ensure that you are only following the ‘Malware domains’ lists and uncheck the nannying lists that are over-reaching themselves in terms of ad-blocking.
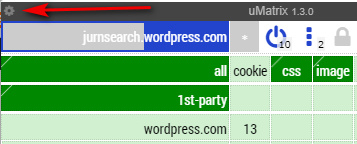
ii) get used to the simple routine of switching it to ‘permissive mode’ and fiddle with per-item blocking later. Giving permission to a site is a one-time four click operation per newly visited URL: Whitelist the ‘all’ cell by clicking on it so it turns from red to green | Un-blacklist the ‘frame’ cell, ditto | then ‘save’ by clicking on the padlock). Then reload the page. You soon pick up the routine.
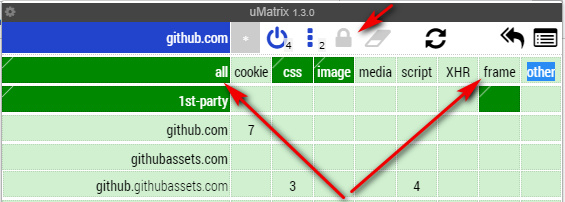
Then, when you have time, you can take another look at what’s loading up when you visit a site, and start blocking useless fluff from regularly visited sites.
The uMatrix whitelisting of a URL takes the form of two lines in an editable list, for instance:
github.com * * allow
github.com * frame inherit
These first go into the My rules | ‘Temporary rules’ list, and then after testing you can “Commit” these to the list of ‘Permanent rules’. To manually edit either list, click on the Edit button under the ‘Temporary rules’ header.
uMatrix looks fiendishly complex at first, due to scary screenshots of its big blocking tables. But spend 30 minutes with it and you’re soon used to it, and can see how easy it is to block stuff in a fine-grained way.