Fragmentology : a Journal for the Study of Medieval Manuscript Fragments
Codex Studies (Italian)
+
Reports and briefing papers archived at APO, Australia’s online archive for policy research.

10 Thursday Jan 2019
Posted in New titles added to JURN
Fragmentology : a Journal for the Study of Medieval Manuscript Fragments
Codex Studies (Italian)
+
Reports and briefing papers archived at APO, Australia’s online archive for policy research.
03 Thursday Jan 2019
Posted in JURN tips and tricks, Spotted in the news
Ah, finally! The latest version of my Opera Web browser (57.03.x) now supports pretty page-like display of raw .XML news feeds, when you encounter them via search or bookmarks. They don’t also offer an .MP3 button, but you just right-click on the tile and “Save linked content as…” to get the .MP3 or similar media downloading.

03 Thursday Jan 2019
Posted in My general observations
If anyone was wondering if I have a Patreon, yes I do, if anyone enjoys using JURN and cares to spare me a few dollars a month. The Patreon is not just for JURN, but modestly helps to support expenses for my various ongoing creative and scholarly activities.

01 Tuesday Jan 2019
Posted in My general observations
I’ve started another mass ‘link-check and clean’ of the entire JURN URL-base, looking for websites that have dropped off Google Search for some reason and are thus no longer found in JURN. My checking and repair will be progressing slowly through the first half of 2019.
01 Tuesday Jan 2019
Posted in New titles added to JURN
Mosaic magazine (indexing essays only)
Journal of Historical Network Research (University of Luxembourg)
Tebeosfera (indexing ‘documentos’ only, for good footnoted essays on the history of euro-comics)
International Gramsci Society Newsletter (1992-2002)
05 Wednesday Dec 2018
New in DHQ: Digital Humanities Quarterly, “Researcher as Bricoleur: Contextualizing humanists’ digital workflows”. A small-scale observational study from 2016, building on a larger ‘Digital Scholarly Workflow’ study. The body is made up of case studies and commentary. Here’s the tale of a search by a historian for “1916” “November” “War Council”:
Audrey, a professor of history, searched for literature on an event that took place in 1916, and for which she had only partial information. Audrey’s search starts with her personal collection of notes written in Word and stored on the internal hard drive. She uses a Word search function that queries the folder for a supposed event name, but this search yields no result. Audrey then switches to her browser and the online search. She logs on to the Penn State library and enters a search phrase composed of three descriptors into the discovery search interface, LionSearch. This attempt does not yield any results either.
“Okay, no problem, I’m going to go to some of my favorite databases,” Audrey says optimistically, and, using the same search phrase, she continues her search in the Historical Abstracts database. “All right, I need another field. It happened in Rome,” she comments still optimistically, and expands her search with one more field, which reads “Rome.” Still nothing. “Seriously?!,” Audrey exclaims with annoyance. “All right, let me just do ‘war council,’ something more specific,” she says with reasserted optimism, and changes her search phrase accordingly. Failure again. “Really?!,” Audrey laments in shock. “I would have thought it was more important.” Audrey then reaches to her bookshelf and grabs a book. She reads through a few pages, trying to find any additional information that could help her search. Nothing. But Audrey is not ready to give up yet.
She returns to her library search and adds “November” as one more search field, trying to make her query as precise as possible. No results. Still, Audrey does not give up, and, instead of adding one more search term, she decides to change her search phrase. She creates a new search phrase, again composed of three descriptors as the possible event name. “Nope. All right, strange,” Audrey says quietly, confident that any further search would be pointless. “You would think someone must have written an article about this. It was the time that the different allies got together and hammered out a strategy…,” she continues murmuring, but discontinues her library search.
Instead, Audrey decides to try her luck with Google Search. She enters the search phrase and the Wikipedia entry pops up right away. “See, that’s the thing,” Audrey comments. “One would love to use more scholarly resources, but I just typed [the search phrase] and it’s up there [on Wikipedia]! Sadly, Historical Abstracts was not of too much use; the most useful one was still Wikipedia,” this historian concludes.
The problem here appears to be that the Supreme War Council of the three allies was created in November of 1917, not 1916. Only by switching the search terms from 1916 to 1917 does the Wikipedia page mentioned appear, so one has to suspect that there was some finessing of the search before hitting Google Search.
28 Wednesday Nov 2018
Posted in JURN tips and tricks, Ooops!, Spotted in the news
Has your ad-blocker (and other scripts) stopped working in the Opera Web browser today? It’s nothing to do with changes made by Google, Bing, Yandex etc.
What’s happened is that Opera has high-handedly decided to disable all adblocker and script-blocker addons from running on search-engine results pages. Thankfully, for now, the browser still has an option to turn off this unwanted and highly dangerous stupidity (disabling script-blockers etc) from the owners of Opera. Here’s the fix…
“For some reason Opera with the latest update have decided to add a new option for extensions that will disable them by default for “search page results”. You’ll have to go to top bar > Menu > Extensions > and then scroll down and tick the box “Allow access to search page results” for your addons. After that it will work normally again.”
You need to do this for each addon that affects search engines and their results, for example…
If you have a JURN link on your Google Search menu bar, via my UserScript, to get it back make sure to also enable TamperMonkey for Opera…
20 Tuesday Nov 2018
Posted in My general observations
Four historic journal archives at Cornell, added to the openEco directory… but they can’t be indexed by JURN.
Journal of Mycology (can’t be indexed by JURN, but noted here)
Transactions of the American Entomological Society (can’t be indexed by JURN, but noted here)
American Bee Journal and American Bee Journal 1861-1900 at the Cornell Online Beekeeping Collection (can’t be indexed by JURN, but noted here)
Annals of the Entomological Society of America (can’t be indexed by JURN, but noted here)
Someone might want to get these onto Archive.org in a more indexable form.
18 Sunday Nov 2018
Posted in JURN's Google watch
It appears that Google Search doesn’t track the Internet Archive (Archive.org) in anything like real-time for the useful content. For instance, see:
site:archive.org staffordshire -cannock -bbc
On this search you have to go to “Last year” to get anything useful from Google Search. With September 2018 being the latest datestamp I can see among those results. This gives the appearance that Google is only indexing Archive.org on a quarterly or bi-monthly basis?
Yet a search for…
site:archive.org + the ‘last week’
… does pick up material from Archive.org, but by the looks of it it’s only the utter rubbish, sex fantasies and spam that Google will want to rapidly exclude or make effectively undiscoverable. My guess is that there’s an ongoing low-level indexing of the new material purely in order to identify the junk, expose it to some user selection to try to sift out anything that’s a false-positive, and that this is then fed in as an ‘exclude’ junk-list for each larger quarterly re-indexing.
15 Thursday Nov 2018
Another new prodding of Google Scholar, this time from the latest First Monday “Testing Google Scholar bibliographic data: Estimating error rates for Google Scholar citation parsing”…
While data quality is good for journal articles and conference proceedings, books and edited collections are often wrongly described or have incomplete data. We identify a particular problem with material from online repositories [where there appears to be] considerable inhomogeneity in the implementation of data standards [and] a mismatch between repository software and the harvesting protocols employed by Google Scholar.
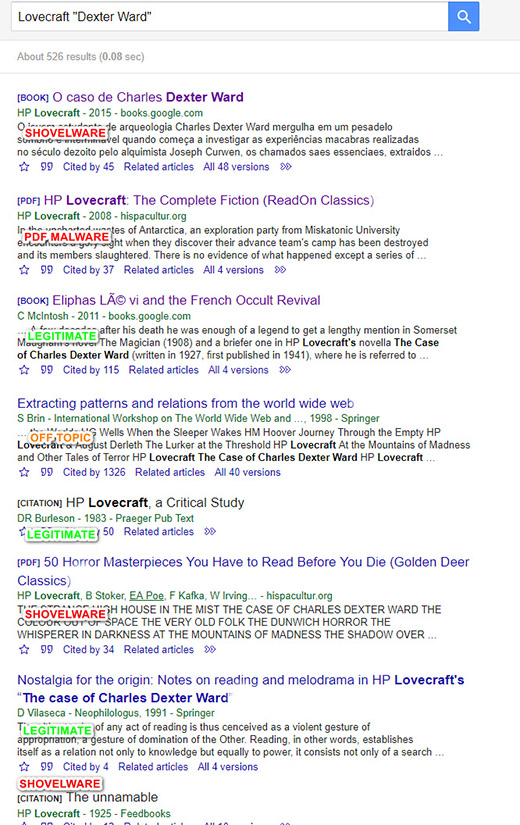
One of Scholar’s other problems is that it includes Google Books results. While 30% of the time its Google Books inclusions can useful, there is no way to exclude Books results. One might want to exclude because Scholar still can’t seem to determine a proper book from a robot-produced shovelware ebook that assembles public-domain content. Scholar has no ‘edition authority’ which states that the Joshi-edited and annotated Penguin Classics edition of H.P. Lovecraft’s “Dexter Ward” is the gold-standard and that it has a text that has been fully corrected of the many textual errors, omissions and editing mistakes of previous decades. Unlike the public-domain shovelware ebooks that flood Amazon and (often) Google Books.
A basic undergraduate level search, for instance, for Lovecraft “Dexter Ward”, demonstrates the problem on the first page. Joshi is nowhere to be seen, and the searcher is hammered by links to shovelware ebooks (or worse), often with citation counts that suggest they are legitimate.