New at Liber Quarterly, “How reliable and useful is Cabell’s Blacklist? A data-driven analysis”.
“How reliable and useful is Cabell’s Blacklist?”
29 Tuesday Sep 2020

29 Tuesday Sep 2020
New at Liber Quarterly, “How reliable and useful is Cabell’s Blacklist? A data-driven analysis”.
28 Monday Sep 2020
Posted in Academic search, Spotted in the news
Internet Archive Scholar, formerly the Fat Cat project, now live and purring. Full-marks for having that rarest of sidebar search-filters, “OA”, though “Fulltext” is presumably broader and thus the one most likely to be used most. It’s also great to see there’s now a keyword-based way to search across all those microfilm journal runs that Archive.org has been uploading recently.
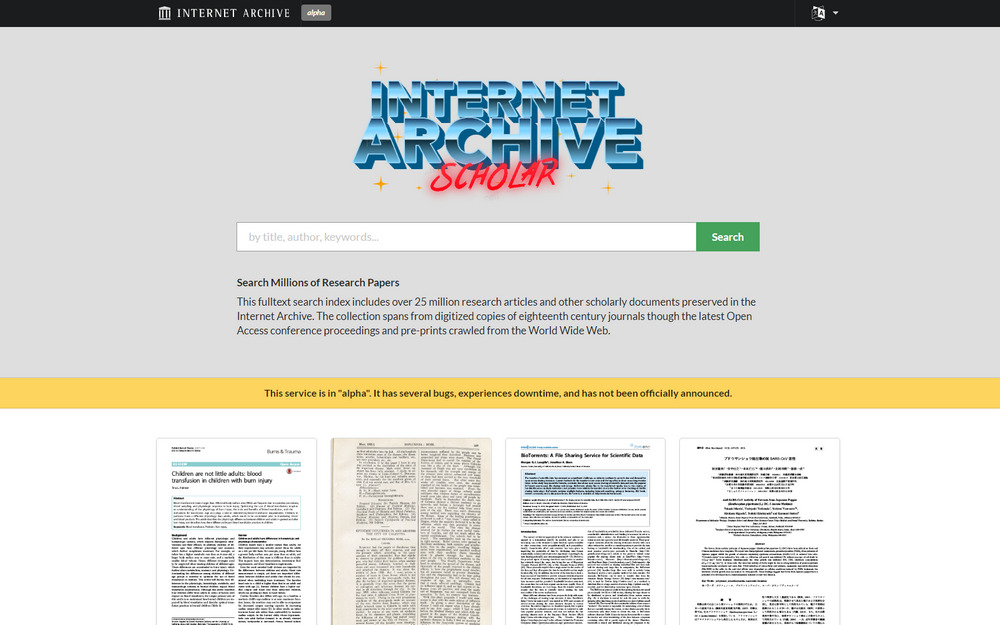
I wouldn’t have used the open ISSN ROAD as a source, nor visually implied that it’s a possible quality-marker. But at least it’s being balanced against the more rigorous DOAJ, and there’s a yes/no flag for both services on the article’s record-page…
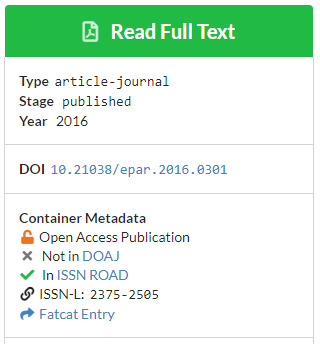
It’s good that the “Read full-text” button goes to a PDF copy at the WayBack Machine, and yet there is also a live link on the record-page that serves to keep a record of the source URL.
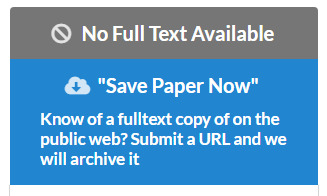
Not all record pages have full-text, though these are very rare. In which case the user is prompted to find and save…
Unfortunately IA Scholar doesn’t appear to respect “quote marks” in search, which is not ideal for a scholarly search engine. For instance a search for “Creationism” defaults to results for “creation”. Nor can it do Google-y stuff like intitle: or anything similar via the sidebar, though I guess such refinements may be yet to come. Update: the command is: title:
A quick test search for Mongolian folk song suggests it’s not wildly astray in terms of relevance. It’s not being led astray by ‘Song’ as a common Chinese author name, for instance, or mongolism as a genetic disease.
How far will Google Search index the fatcat URL? Will they block it from results in due course, for being too verbose and swamping results? Or just tweak the de-duplication algorithm to suppress it a bit? Well, they’re indexing it for now, and as such it’s been experimentally added to JURN. It may well come out again, but I want to test it for a while. If Google Search fully indexes, that should theoretically then give JURN users a way into all the microfilm journal-runs that Archive.org that has recently been uploading.
28 Monday Sep 2020
Released in June 2020, a new consultancy report titled “Equitable access to research in a changing world: Research4Life Landscape and Situation Analysis”. This surveys the pressures on the Research4Life aid programmes. Established 20 years ago, Research4Life gives developing countries “free or low-cost” online access to journals and books from some 175 publishers. Along with other aid initiatives, this means that African universities often have better free access to journal databases than do some academics in advanced nations. The new report makes no recommendations, but a key point to note is that…
… some of the most relevant and influential research undertaken in low-and-middle income countries happens outside academia: in specialised research institutes, think tanks, or government-backed research agencies. In some countries, research agencies and institutes conduct research in national priority areas and have direct access to and influence on decision-makers” [yet] “these non-governmental organisations have in the past been excluded from open access debates, and may be unable to take advantage of initiatives such as Research4Life.
It could be useful to quantify that “may”, through further research. Do developing nations find roundabout ways to include their research agencies in Research4Life, such as giving off-campus agency researchers special log-ins to access the national university system? Or are such arrangements rather moot, in the age of open-access and Sci-hub? If not, would there be a real benefit if Research4Life were to be extended to bona fide government research agencies and suitable NGOs? How much would such an expansion actually cost, and what could the returns be in such nations?
27 Sunday Sep 2020
Posted in Open Access publishing, Spotted in the news
New from the University of Wolverhampton in the UK, “Open Access Books in the Humanities and Social Sciences: an Open Access Altmetric Advantage”…
“examines the altmetrics of a set of 32,222 books (of which 5% are OA) and a set of 220,527 chapters (of which 7% are OA) indexed by the scholarly database Dimensions” in Humanities and Social Sciences.
27 Sunday Sep 2020
JURN is now as up-to-date as it can be, ready for the “back to university” crowd. I’ve completed a link-check of the full URL base, checking for continued presence of an indexed URL path in Google Search. The full path is checked, not just the top domain (e.g. foobar.foo/foo-foo/journal_of_foo/articles/ and not just foobar.foo). This checking process has been slow, taking about 18 months, on and off.
Of course, a few URLs may still have newly broken in the meanwhile. But the core URL base is kept fresh by a regular check of the key home-page URLs, as organised and listed at the JURN Directory of arts & humanities journals (English-language journals only). This Directory was link-checked and updated in mid September 2020. Also recently link-checked, back in July 2020, was JURN’s openEco Directory of over 800 journal titles variously related to the study of wildlife, ecology etc. Please update any local copies you may be keeping.
27 Sunday Sep 2020
Posted in Ecology additions, New titles added to JURN
Journal of Facade Design and Engineering
Journal of the Asiatic Society (India)

Journal of Coastal and Hydraulic Structures
BioDesign Research (indexing annual TOCs pages only)
27 Sunday Sep 2020
Posted in JURN tips and tricks
New, My Little Regex Cookbook as a printable eight-page PDF. It has numerous working examples of useful regex for Notepad++ users working with data extraction and text lists. All tested and working in Notepad++.
This is my expanded and now prettified 1.3 PDF version of what first appeared here as the post “Some useful regex commands for Notepad++” in May 2019.
Download: little_regex_cookbook_2020.pdf
26 Saturday Sep 2020
Posted in Spotted in the news
Detected academic plagiarism “can” now negatively affect an individual’s ‘social credit’ score in China. Masters degree students will now also have a compulsory “class” to “learn about academic ethics” in essay writing. I’d prefer to hear “will” rather than “can”, and “semester-long course module” rather than “class”, but it’s a start.
25 Friday Sep 2020
Posted in JURN tips and tricks
There’s a relatively new entry in genuine Windows freeware for complex text-manipulation, and this hadn’t been found when I made my summer 2019 survey of Freeware for cleaning and manipulation of text lists.
It’s TextWorx by bgmCoder, a “Universal Text Manipulator”. It lives up to the name, in terms of being able to use it with any text-editor. Highlight the text block you want to work with. Press a keyboard shortcut. Up pops a well-organised tool offering a huge range of “advanced text-manipulation routines”.

The default keyboard shortcut required to trigger the menu is a bit of a contortionist show-stopper, or else it requires you to remove your hand from the mouse:
Win key + K or Win key + shift + K.
But the shortcut is not hardwired and can be changed in the .INI file. And it’s easy enough to trigger a keyboard shortcut with a mouse-gesture. Choose a gesture that ends up somewhere suitable on the screen, since your mouse-cursor position is where the TextWorx interface will appear.
What it doesn’t seem to have is regex functions. It can’t thus function as a handy regex ‘key-ring’. For instance it can’t do things like “Extract all text found between KEYWORD1 and KEYWORD2 to a new List”. For that you’d want regex or Sobolsoft’s £20 “Extract Data Between Two Strings” utility software, which saves the extracted substrings as a list. Or you could save £20 by doing the same with this tested-and-working regex and a copy of the free Notepad++…
FIND: .*?KEYWORD1(.*?)KEYWORD2|.+
REPLACE: \1\r\n
24 Thursday Sep 2020
Posted in Uncategorized
Some free WordPress.com users will be used to responding to the Bell in the top-right of their blog’s User Interface. They may now be wondering what’s happened there. Clicking on the Bell should open a sidebar list of recent posts and responses. It now never loads.
![]()
It’s part of the slow and stop-start changeover from the old editor to the horrible new Block editor (the free Open Live Writer desktop software is the alternative for free users).
To get to your Bell alerts now, when in ../wp-admin/.. you instead swing over to the other side of the screen, and click on “My Sites”…
![]()
This then gets you the newer interface…
![]()
Swing back over to the Bell, now blue. Your alerts will now load…

Then you click back to the ../wp-admin/.. UI.
As for Open Live Writer, it only lacks access to this Bell, and to the blog’s uploaded Media Library. All other WordPress blogging functions are in there, though sometimes you need to right-click on a seemingly-plain icon to find its advanced options (like loading a list of the scheduled posts).