Pandoc is a useful universal document converter utility. Yet using the free Pandoc on Windows is often assumed to be about typing arcane command lines into a command prompt, and hoping for the best.
But now there’s a nice free and open source front-end for Windows, for those who just want the markdown. The 2019 PanWriter is a delightfully elegant and simple markdown writing pad for the rest of us.1 It’s a speedy Windows desktop install, and it didn’t even need to be told where Pandoc was on my PC. It just ‘knew’.

Even if you don’t need another sweet text editor, PanWriter also serves as a document importer and converter utility. Just load up a HTML page you saved from the Web, and it instantly converts all the HTML code to markdown. I loaded a few really complex pages and it didn’t blink, instantly presenting a clean markdown conversion.
Why would one want to convert HTML to markdown, you ask? Because it places the HTML and other elements onto single lines, while retaining Web links in place. Such lines are far easier to extract data blocks from. Compared to fiendishly nested HTML code that sprawls across multiple lines.3

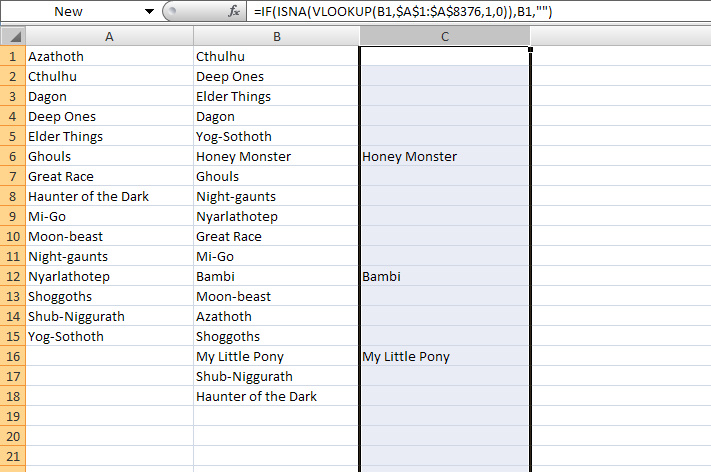
Picture: the above web page (just some random Met Museum image search results) in Notepad++ as markdown.
Once the markdown text is in Notepad++, then a macro can have its way with it. This can ‘Find and Mark’ the repeating line-blocks2 containing the data you want to extract and clean (e.g. search-engine results). These can then be copied out to a new tab (Top Menu: Search | Bookmarks | Copy Bookmarked lines). Then the macro can run various operations that fix up the text a bit more,4. before finally saving the cleaned list back to HTML via the user-friendly MarkdownViewerPlusPlus plugin for Notepad++.5
So the basic workflow here is:
1. Get your search results and save your Web page(s) as usual. There’s no need to painstakingly select-copy-paste just part of the page.
2. Use a joiner utility (TXTcollector) to join all the saved pages.6 Open the saved HTML with PanWriter and it instantly auto-converts into markdown.
3. Open the saved markdown with Notepad++ and run your cleaning and text-sorting custom macro on it.
4. Copy-paste the resulting linked data list as HTML to your blog etc. (Or to .CSV for Excel import and sorting).
The above is a more advanced and robust version of my recent home-brew workflow, which suggested a browser addon and manual copy-paste. That was more suitable for occasional use by bloggers and academics who can’t afford sophisticated data scrapers (and the proxies to run them).
This workflow has the advantage that: i) it’s all free software; ii) it doesn’t need you to pay for and burn through proxies in your paid scraping software; iii) as long as you have the HTML in your browser it can be grabbed, and it basically doesn’t matter how complex and nested the page code is, as it’s all going into Markdown; and iv) collection can be automated with Windows automation software (JitBit) etc, and processing can be automated with Notepad++ macros. But it is obviously not suited to automated scraping of millions of records from multiple shopping sites — if you’re into that game then you should have the cash to buy in those datasets.
Notes:
1. There are also two old GUIs for Pandoc, over on GitHub. One there is nice and simple, and has batch… but it crashes and fails on 64-bit Windows, as the developer admits in his readme. The other GUI at GitHub was tried and runs on 64-bit Windows, but seems far less user-friendly. There are also a half dozen Python scripts projects that do this.
2. Marking and exporting lines in Notepad++ can’t currently be done for multi-line nested HTML code, which is why a HTML-to-Markdown conversion is so useful. While multi-line block marking can be done between two keywords [ Find | Mark | Regex with Newline | then paste in…
(?<=STARTWORD)([\s\S]*?)(?=ENDWORD)
…this only places a single mark at the top of each marked and highlighted block. It does not run a line of marks down the entire block.
3. Yes, I know about XPath, but with a complex Web page it's: i) fiendishly tricky to do the initial puzzling out of what needs to be captured; ii) often fails to then grab what’s needed; iii) and has even more difficulty in aligning data fields when used as a browser addon.
4. Note that multiline search-replace needs to be done as \n commands not plugins, in macros. Also that Crtl + Home will get your cursor back to the top of the text.
5. Sadly one can’t yet use Notepad++ as the initial importer/converter, as it has no such plugin at present. I’ve looked. There are a couple of possible Python scripts but support for the Python plugin in the latest Notepad++ is a bit of a mess at present, with plugin structures being swopped around and then reverted. So that’s not really an option, unless you want to fall right back to version 5.9 or thereabouts to use a script.
6. Update: If you have no absolute need to keep the saved HTML pages as backup, then Clipboard Magic is lovely little Windows freeware that keeps copies of each clipboard, then when done you “Copy all clips to clipboard” and paste to Notepad++. Or if you still use an older 32-bit Notepad++ you can use the fine MultiClipboard plugin.