Retraction Watch Database
27 Saturday Oct 2018
Posted in Spotted in the news

27 Saturday Oct 2018
Posted in Spotted in the news
26 Friday Oct 2018
Posted in JURN tips and tricks
It’s the back end of 2018 and there’s still no really useful and comprehensive search tool for recent blog posts, other than the main Google Search. And even that is iffy. Given that we’re approaching Halloween, I decided to do a quick group test with the simple keyword Lovecraft. He’s a good choice because so much utter trash floods onto the Web in his name. If a search can deal with Lovecraft, it should be able to handle much else.
* Google News: Can filter by ‘blogs’ and by ‘date’, but the results are laughable — are there really only eight blog posts on Lovecraft in October 2018, from worthy long-form and timely-news bloggers? I think not. (Another test for ‘Staffordshire’ suggests News | Blogs is almost all just press-release outlets and similarly worthless pseudo-blogs).
* Google Search: The inblogtitle:keyword modifier is no longer useful in search, as it now returns only 10 irrelevant results when used with Lovecraft. One used to be able to find sites that Google ‘knew’ were blogs, and had a keyword in their main blog title. Google Search has also removed ?tbm=blg from their URL options.
* WordPress.com internal cross-blog search: Simple to use, the results looks pretty, but it obviously has very mediocre coverage of its own blogs. Many expected and well-respected blogs do not appear at all. Users need to be aware that they are not seeing results from the entire range of non-spam WordPress.com hosted blogs.
I would suspect that DuckDuckGo may be using this WordPress.com results set as a de facto anti-spam whitelist, since that would explain its curious big gaps in the coverage for WordPress.com blogs. The same may be true of the dismal Bing — the only saving grace for which is the excellence of the Bing News | Most Recent results, which you can RSS-ise by adding &format=rss to the URL. By comparison, NewsNow is nowhere.
* You Got Blogs, a Google CSE: Fairly good at pulling the top three currently-active blogs to the top of the results, but thereafter turns to mush. If the user then sorts by Date on a single keyword, the results are far less useful, mainly because You Got Blogs is indexing all *.wordpress.com/* pages rather than just the blog posts via *.wordpress.com/20*/* You Got Blogs is reliant on Google Search, since it’s a CSE, and thus for many blogs Google will only show the most recently-indexed post or else just the front page (e.g. you make seven posts a week, but Google will only show searchers the post it has most recently indexed, and the others will be un-findable). It’s thus an impossible balancing act for You Got Blogs (or any other blog-focussed CSE): if they don’t do a global index of *.wordpress.com/* then they miss a whole lot of results.
* Regrettably setting up a Google CSE (for *.wordpress.com and *.blogspot.com etc) is not an option. I’ve tried it and practice it doesn’t work well, when one sorts by Date. It’s sort-of-ok on a straight search, if making a first search looking for blogs on one’s topic, though the main Google Search would do better. A CSE picks up and lifts to the top of the results some very out-of-date and moribund blogs, and obviously can’t deliver usable sort-by-date results.
* Social Mention. Search restricted just to ‘Blogs’. Pathetic results from ‘Blogs’. No results at all, for ‘Microblogs’. Top three results were very similar to the WordPress.com internal, then a huge gap in time. My guess is they’re blending together the WordPress.com and Bing APIs, and to no great effect.
* DuckDuckGo: Should, theoretically, be good. But is mediocre. It all-but ignores key Lovecraft blogs, blogs which rank very highly in Google Search. I should note that the Duck is excellent in many other respects, especially the relevance of its Image Search. But is still lacks breadth and depth.
* Instant RSS Search Engine. No longer appears to work, even when tested in multiple browsers.
For niche news gatherers wishing to supplement their RSS feedreader and break out of the tiny-minded Twitterbubble, the best option at the end of 2018 is thus to set up a bookmarks folder in your Web browser with the following:
site:wordpress.com/2018/10/ “Lovecraft” -zombie -game -movie
site:blogspot.com/2018/10/ “Lovecraft” -zombie -game -movie
Vary according to your desired keyword and knockout words, obviously. These URLs will work because all blog posts on Blogger and WordPress have the date embedded in their URL.
These bookmarks should be set to run on Google Search and DuckDuckGo and Yandex (the latter with a &lang=en English only filter in the URL). Right-click on the finished Bookmarks folder, select “Open All” and they all load.
Of course, this doesn’t pick up self-hosted blogs, only the free ones. And, obviously you’ll have to manually go in and incrementally change the date numbering in the target URLs, at the end of each month. Thus it’s not a perfect solution. (Nor can this solution be amalgamated into a Google CSE, for the reasons stated above).
Once the searches have loaded, switching through to a “week” or “24 hour” view will require the copious use of Google Hit Hider by Domain, to weed the spam and unwanted results. Google Hit Hider knocks out unwanted domains from search results, and does it very well. (Google Hit Hider can run on Yandex, it just needs the results reloaded, in order for its blocking buttons to appear).
Even having set up such a one-click Bookmarks folder, we also still have the problem of Google Search sometimes only offering the front page of a timely and frequently updated blog, rather than its most recent post URLs. In practice though, for a ‘last 24 hours’ search, you don’t actually need a site: modifier…
site:wordpress.com “Lovecraft” -zombie -game -movie
All you need is ‘last 24 hours’ filter alone, and Google Search will lift some of the best content into the first two pages of results. Kind of useful, as it can thus catch self-hosted blogs, albeit jumbled among legacy news sources and updating catalog sites etc. Even so, you’ll want Google Hit Hider when working at the 24 hour level.
Also useful, inside your new folder, will be a similarly hard-coded Google Images search URL for the last 24 hours or week…
“keyword” -pinterest -youtube -twitter -wikipedia -tumblr -instagram
… and so on. It only takes a few seconds to visual check the results, and such timely visual results are often useful re: new books, conference posters etc. Keep eBay listings in the mix as they can suggest interesting blog post topics, about old vintage stuff. Again, we’re not keying the search to blogs only, and thus Google Hit Hider is your friend here (it also works on Google Images results – block on Google Search, and it’s also blocked on Images).
There are of course also a whole bunch of “request a demo” agency services which claim to offer social media sentiment tracking. They seem to be of the ‘if you have to ask the price, you can’t afford it’ sort. There’s one free and public service worth a look, Social Searcher. Very slow to load a search, but it’s pretty and it works. It’s no use for blogs, though, but seems useful if you want to quickly glance across recent Facebook and Twitter posts. It covers some other ephemeral sharing sites, but their signal gets swamped by Facebook and Twitter. Not that that matters much as it’s almost all blather and parroting, of no news value. To prevent results turning into a wall of hashtags, the tags panels can be blocked in uBlock Origin with social-searcher.*##[class^="rezults-item-tags"]
24 Wednesday Oct 2018
Posted in JURN tips and tricks, Spotted in the news
I’m pleased to see that Text Cleanup 2.0 is now freeware. It’s Windows desktop software from 2003 that “fixes” text automatically when you copy-paste it. For instance, by unwrapping a chunk of text that has hard line-breaks. Text Cleanup has a nice balance of power and ease-of-use, can save user presets, and still runs fine on a Windows 8.x desktop.
24 Wednesday Oct 2018
Posted in Spotted in the news
The Art Institute of Chicago now has 44,000 items from its collection downloadable as pictures under a CC0 licence. I did a test search for cat. What struck me first was the rich range.
My excitement was dampened when I realised that most of these results had no hi-res download. What I should have done was spotted the easy-to-miss faded “filters” button, up top, which when clicked pops out a sidebar. In the sidebar you can tick to filter by “Public domain”, which gives you the results with the downloadable images.
The filtered results are still fairly impressive, but of course lack the nicer “wow” illustrations made after about the 1910s. Some images download without file extensions, possibly because they already have a . in their title (e.g. “Honorable Mr. Cat”)…
Some of the search substitutions are rather dumb, for instance if you search for plague you get plaque.

The pictures seem to mostly be around 2,000 to 3,000px and 96dpi. There’s no sign-up needed, and access is free and public.
22 Monday Oct 2018
Posted in JURN tips and tricks
The problem:
 Hmmm, not really adding a lot, are they? Nearly all news reports these days use shovelware stock/library photography or logos of some kind, or are occasionally grabby click-bait. These irrelevant distractions can be blocked with no loss, allowing you to focus on the headline, source and snippet.
Hmmm, not really adding a lot, are they? Nearly all news reports these days use shovelware stock/library photography or logos of some kind, or are occasionally grabby click-bait. These irrelevant distractions can be blocked with no loss, allowing you to focus on the headline, source and snippet.
The solution:
Block image thumbnails of news media pictures from appearing in your Google News search results. To do this efficiently and precisely, in the uBlock Origin browser addon, go: Dashboard | My Filters | then paste in these two lines…
google.*##[id^="news-thumbnail"]
google.*##[alt^="Story image"]
At July 2020, also add:
google.*##*.sYpfDb
google.*##*.QyR1Ze
Then “Apply changes” and exit. Reload the Google News results, and the thumbnail images are gone. And gone in an elegant manner, without leaving behind an ugly block of ‘alt’ text.
Why two filters? Because while most Google News thumbnails have “news-thumbnail” in their id class, the top one per page does not. To also block this thumbnail you need the second cosmetic filter, which blocks any images with an alt tag which has the phrase “Story image” in it.
The empty padding can be removed with…
...com##a.top.NQHJEb.dfhHve
...com##.xA33Gc
… where you add google.dot in place of the three dots.
These filters have the advantage of not interfering with thumbnail loading over on Google Images, Google Books etc. Though if you do want to block book cover thumbnails on Google Books, for some reason, then add this line…
...com##*.th
(I also have a post on how to block YouTube’s new animated ‘thumbnail previews’ of videos in its search results)
21 Sunday Oct 2018
Posted in JURN tips and tricks, JURN's Google watch
Here are some updated fix instruction for the latest GoogleMonkeyR UserScript, which many desktop power-searchers use to give their Google Search results a three-column multicolumn layout.
* Problem: the script breaks Google Image search results, by running on such searches. Specifically, the script appears to be preventing the central ‘slider’ div from opening up, when an image is selected from the Google Image search results.
* Solution: In your Web browser, access the raw GoogleMonkeyR script. For instance, in Opera this is done via: Extensions | Tampermonkey | Installed UserScripts | GoogleMonkeyR | Edit.
You then need to paste in a line of code that explicitly turns off GoogleMonkeyR, but only whenever the browser is running a Google Images search. To do this, add the following line to the header of your GoogleMonkeyR script, below all the // @include lines…
// @exclude http*://www.google.*/search?*isch*
Google Image searches have “isch” in their URL, so we can grab onto that and exclude such URLs. Save (click the disk icon) and exit. You should now be able to operate the Google Images results as usual, which still retaining your usual three-column layout for the main Google Search.
20 Saturday Oct 2018
Posted in JURN metrics, New titles added to JURN
JURN’s entire URL list has now been checked, looking for continuing presence of the URL path on Google Search results. This is the annual re-check of the core list that drives JURN’s search results, not the approx. six-weekly re-check of the JURN Directory.
I checked the specific URL path being indexed, and not just the basic domain. For example, for ITJ: The Intel Technology Journal, the URL checked was http://www.intel.com/content/www/us/en/research/ rather than just http://www.intel.com.
Broken URLs were re-found and fixed, or deleted as required. Roughly 1 in every 50 URLs had broken.
18 Thursday Oct 2018
Posted in JURN tips and tricks
It’s surprisingly difficult to discover the right settings in .ZIP-file handling software to extract multiple .ZIP files into a single subfolder. Without making multiple subfolders within that new folder, one for each .ZIP file. That latter arrangement is not so good… if you have scans of 10 journals in 10 .ZIP files and want to visually pick out just five images from their combined 800 pages.
The popular 7-zip for Windows has what appear to be the right settings (“No pathnames”), but fails to respect this. I tried multiple configurations, but 7-zip always extracted each .ZIP into its own subfolder regardless.
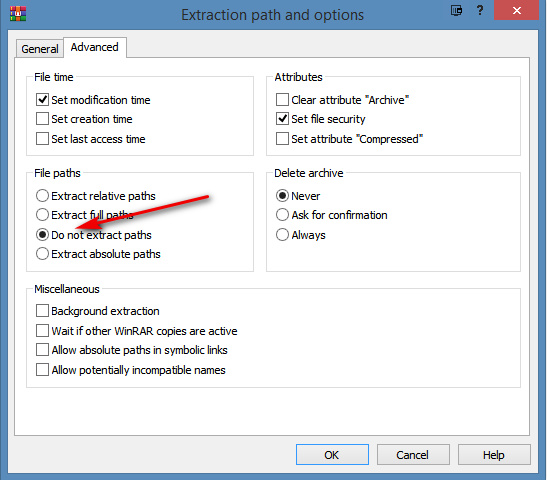
The solution is WinRAR. Use its “Do not extract paths” setting when extracting…
14 Sunday Oct 2018
Posted in JURN tips and tricks
How to enable text search of ePub files, in the SumatraPDF reader…
1. Go to: top left corner icon | Settings | Advanced Options.
2. At the top of Sumatra’s config file you’ll see:

3. Change false to true. Save and exit.
Mostly you’ll be sending an ePub over to a mobile device, where it will be handled by better apps. But the choice of reader is limited on the Windows desktop where you may also be archiving the .ePub files, and where you may want to sometimes hop into one of the files to swiftly find a specific name or title.
I don’t yet know of desktop freeware that can search across and inside of multiple .ePub and .mobi files.
09 Tuesday Oct 2018
Posted in Spotted in the news
NAVER Academic is an attempt at a Google Scholar-alike for South Koreans. It’s fast and neatly designed, and is interesting because (unlike Scholar) it has a “Free” filter for its search results.
My quick test search suggests it’s mainly interesting for those seeking non-English content from the region. A search for mongolian folk song filtered by “free” had 19 results. Six of these had English titles and were checked…
1. English abstract. No full-text.
2. English abstract. No full-text.
3. Very short English abstract. CORE record. No full-text.
4. Short English abstract. CORE/JSTOR record. No full-text, DOI link led to 20 Euro paywall.
5. Very short English abstract. CORE record. Link led to full-text PDF “Music Classes of Elementary School in Mongolia” in Japanese.
6. English abstract. No full-text.
Of the 19, only one was actually free. Thus the main problem here is that “free” does not = “full-text”, unless you have academic log-ons within South Korea.
