
The free open-source Tesseract OCR 4.0 for Windows (beta, 64-bit), released 14th April 2018.
“The Mannheim University Library uses Tesseract to perform OCR of historical German newspapers. Normally we run Tesseract on Debian GNU Linux, but there was also the need for a Windows version. That’s why we have built a Tesseract installer for Windows.”
The Tesseract engine was apparently originally from Google, in use there at Google Books, but Google made it open source.
Tesseract 4.0 supports OCR in a range of old and ancient letterforms including German blackletter (aka Fraktur, in popular parlance ‘Gothic’), but these need to selectively enabled at install…
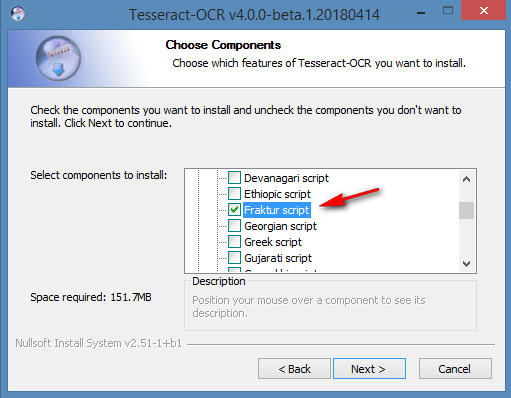
Once installed there are a few Windows GUI front-ends to choose from, with which to operate Tesseract. gImageReader is 64-bit Windows and current. On their forums I found a gImageReader beta version that is newly-compiled for Tesseract 4.0 beta. That needs to be launched in Windows Administrator mode, and then it also seems to require a Fraktur download, in order to handle OCR of German blackletter letterforms…
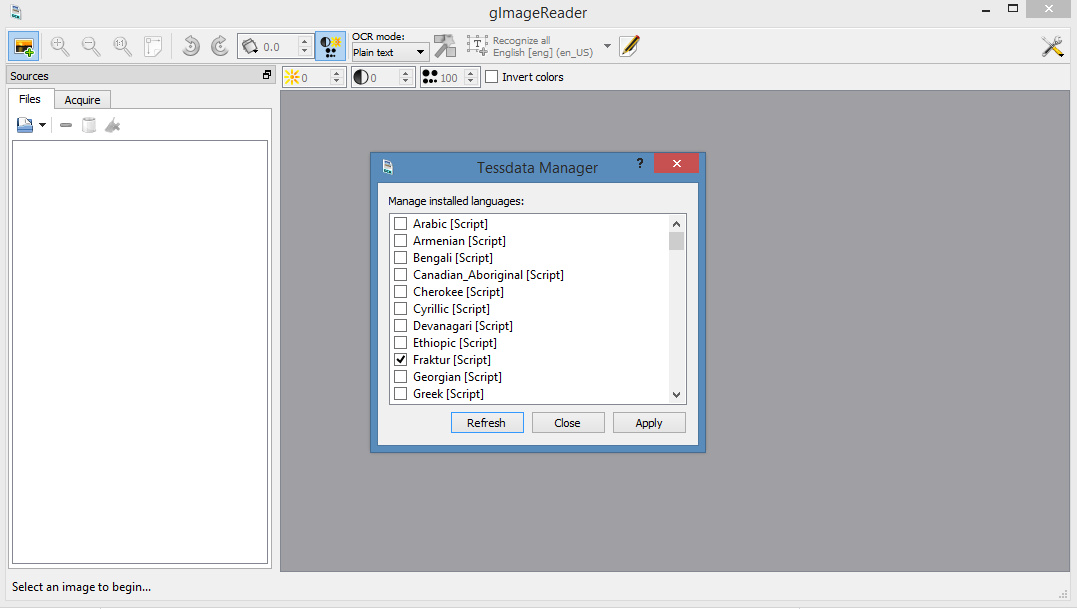
I’m assuming that gImageReader ‘knows’ where Tesseract 4.0 is, and hooks into it automatically. Because I didn’t need to set any file-paths to it, in gImageReader.
Once gImageReader is set up and the Frankur toggle/icon is switched, even when taking a screenshot the OCR results were pretty good…
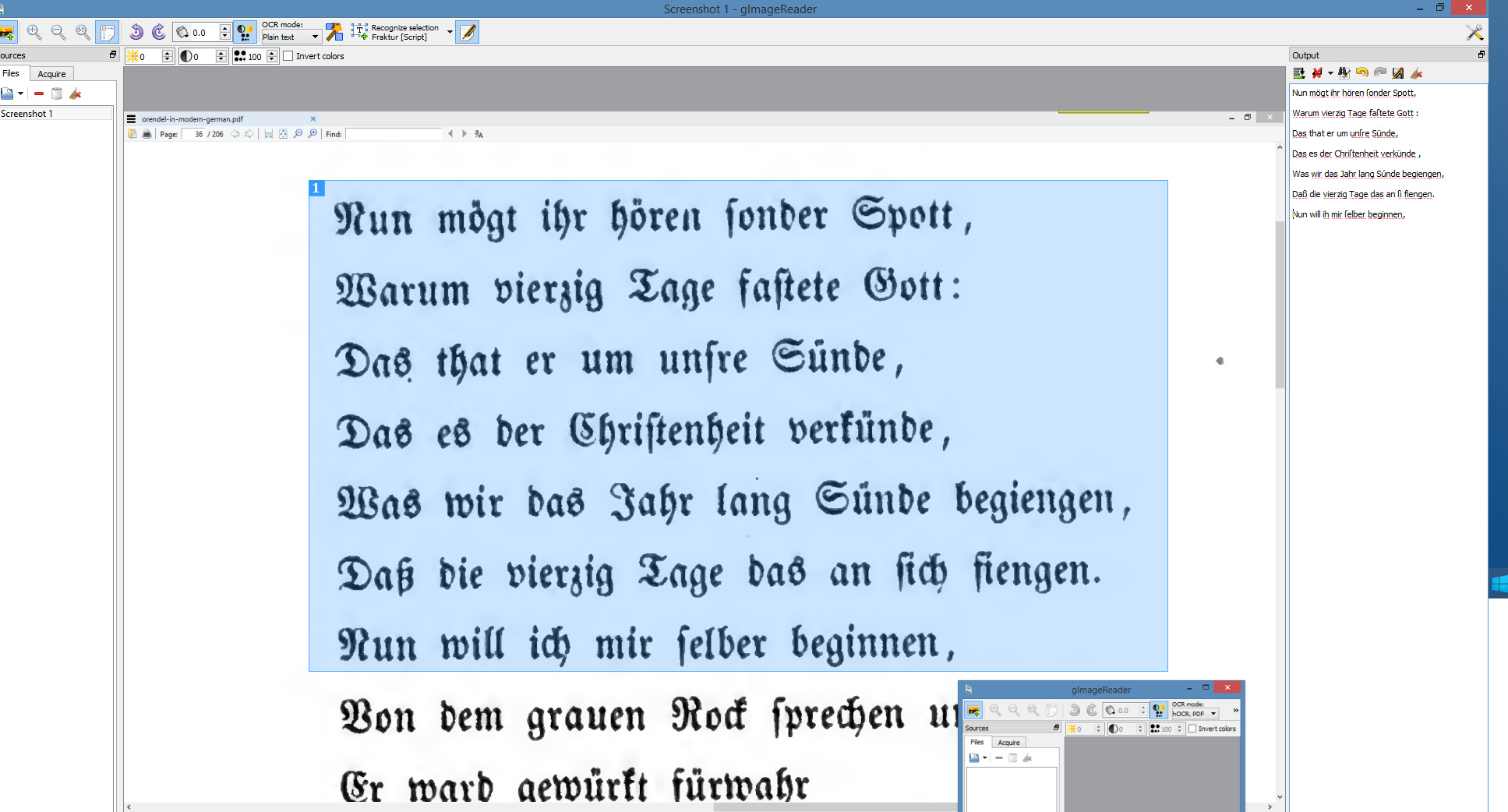
It can also handle complete PDFs, and seems to go at about 15 pages per minute on a modern desktop PC. Nice to have, and (in combination with Google Translate) useful if your research takes you back to the German literature of pre-1938 — but you can’t read German and certainly not in blackletter.
There are probably online sign-up services that can do the same, these days, where you do a sluggish upload and have to deal with time-outs and usage-quotas etc. But I prefer the ease of having one’s own Windows desktop software.


