VideoSubFinder is Windows freeware to auto-detect and extract hard-coded subtitles from videos, saving the results to a series of screen grabs — containing only the subtitle lettering at large size and thus ready for OCR. VideoSubFinder appears to be the best option for occasional use by media archivists, and also publishers and editors who want to extract to text.
It’s been tested by me and is working nicely ‘out of the box’ on an old 17 minute video. It does not appear to have native dependencies other than requiring the Microsoft Visual C++ Redistributable for Visual Studio 2017, which most Windows users will already have installed. Its output does however require Finereader or similar for OCR processing (see below).
The use-case here is: you have an old interview where where the audio is degraded and/or the speaker has heavily accented English, or where the subtitles are translations, which means you can’t just upload it to YouTube and have closed captions automatically generated in a twinkling by eager Googlebots. But you do have good hardcoded English subtitles on the video frames, which someone spent time creating — perhaps decades ago.
Using the software is tricky, despite the simple interface, as there’s no Help. My noted workflow is as follows…
1. Open your video.
2. Scrub the video’s timeline to the desired starting frame. Then on the top menu: Edit | set Beginning Time.
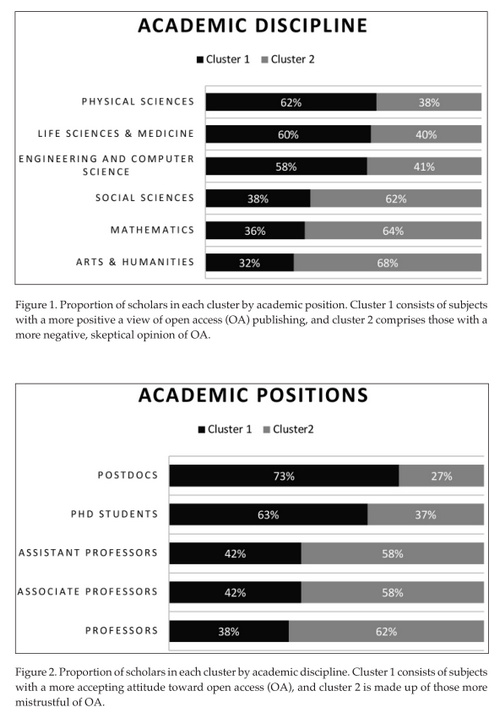
3. Drag down the little sliders (they look like black fly-specks and are easily overlooked) seen in the corners of the video, so as to precisely frame the area where the subtitle line appears.
4. In the lower panel, switch to the OCR tab and press “Create cleared TXT images”. Subtitles should be extracted from the video frames as ‘lettering only’. This should take a while, but less time that actually playing the video. Now might be a good time for a coffee break.
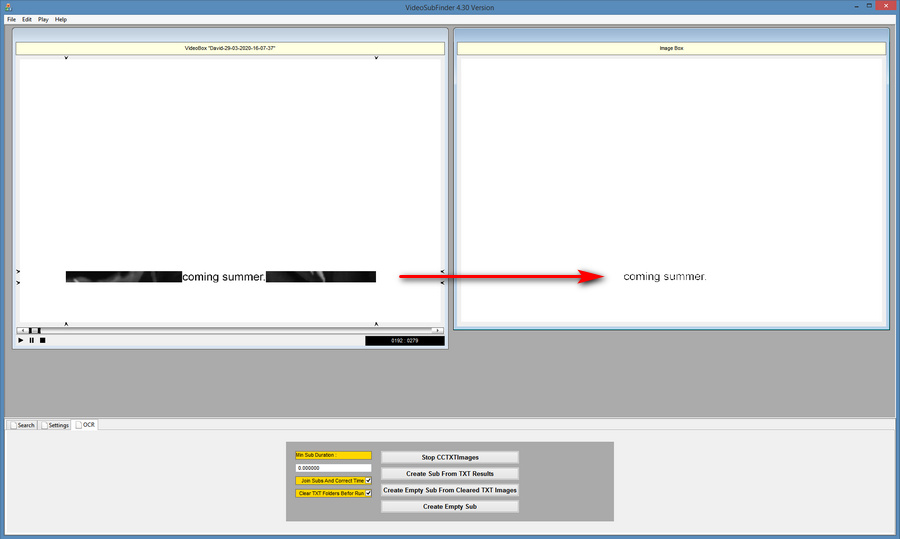
5. Once this process has completed, you then open up the software’s TXTImages folder…
..\VideoSubFinder_4.30_x64\Release_x64\TXTImages
And inside there are a series of large .JPEG images containing the extracted text as large cleaned image-captures, all ready to be OCRd.
So far as I can tell there’s no built in OCR engine with VideoSubFinder, nor any way to plug one in. So now you switch to OCR software such as Finereader.
6. In Finereader, sort the files correctly and then open all the files (Ctrl+A) found in the ..\TXTImages folder. There is no need to resize as Finereader can handle humongous file sizes, unlike the full Adobe Acrobat. Processing should be straightforward and fast, just let it finish. Then save the results out to a single .TXT file and edit.
Apparently, for making new .SRT subtitles, one can then also use this Finereader output file with the “Create Sub From TXT Results” button in VideoSubFinder, and the result should be a timecoded set of subtitles. But for the purposes of an archivist or editor extracting a text interview, this step is not needed.
If you’re going to need to do this sort of thing often and you have a generous boss, then Microsoft Video Indexer is likely to be your friend.