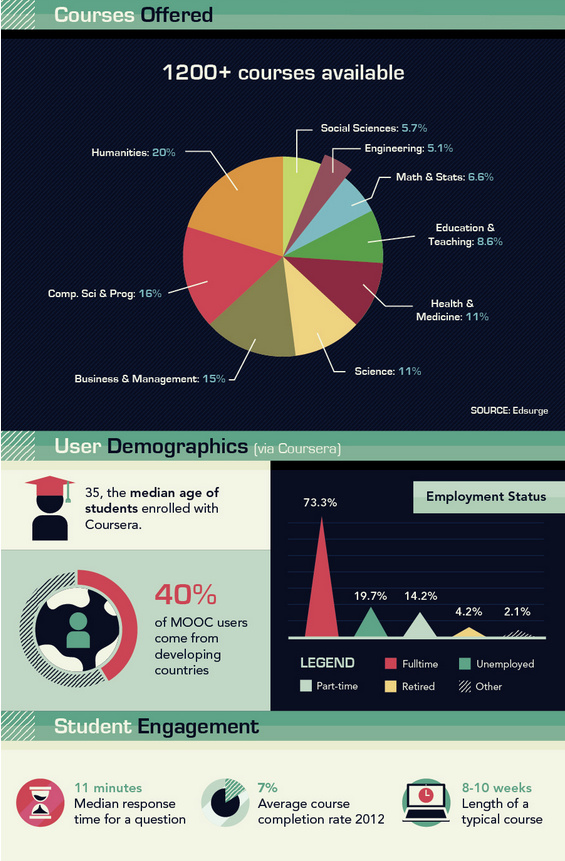
New White Paper from commercial publisher SAGE: Discoverability of Scholarly Content: Accomplishments, Aspirations and Opportunities, written after the moment…
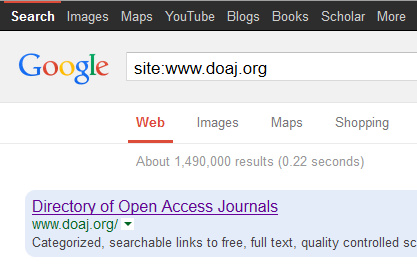
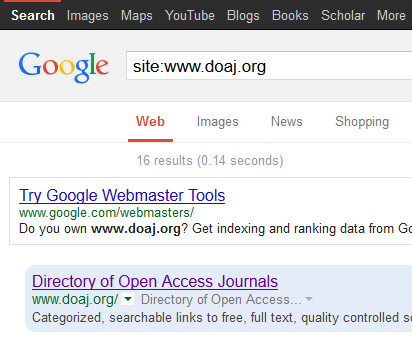
“in 2013, [when commercial paywall] academic content providers around the world were forced to consider alternate methods of open-web discoverability when Google’s primary web search ceased its special treatment of access-controlled scholarly materials”
The consusus here and elsewhere seems to be ‘just add metadata’ to open content, and it will slot right into existing closed discovery systems. Good luck with that one, and don’t forget to shut the stable door.
Interesting comment spotted in the paper, in relation to the oft-heard complaint that Google uses closed proprietary search algorithms…
“The research also noted the variability among [academic library Web-scale] discovery services’ proprietary search algorithms, which — lacking transparency — disallows local customization, which libraries and end users expect.”
What it doesn’t mention is the quality of the ranking done by the proprietary search algorithms in services such as Summon. To see what I mean, try the dozy search | what is history carr | in Summon, then try it again in JURN.