I did a quick experiment in making a Custom Search Engine via DuckDuckGo‘s link-chaining feature. In this experiment I enable a search across a small group of reputable crowdfunding services, via this search in DuckDuckGo. The search format is…
"open access" site:patreon.com,gofundme.com,peerbackers.com,mysherpas.com,wedidthis.org.uk,crowdcube.com,cofundos.org,indiegogo.com,rockethub.com,kickstarter.com
Works fine. WordPress.com refuses to embed an active link that contains “a phrase” (it’s the inverted commas, presumably), but this test link should work.
Unfortunately chaining a list of URLs appears to turn off DuckDuckGo’s intitle: search modifier, at least when searching for a phrase. But intitle: does work when using a single keyword, in a search such as…
intitle:journal "open access" site:patreon.com,gofundme.com,peerbackers.com,mysherpas.com,wedidthis.org.uk,crowdcube.com,cofundos.org,indiegogo.com,rockethub.com,kickstarter.com
A keyword / phrase that veers more into popular culture (such as Lovecraft) seems to cause Kickstarter results to swamp the search results.
I also noted that the search results from the above example fail to distinguish between “open access” and “open-access”. Adding +, as in +”open access”, fails to force a verbatim search. There is obviously some slight wiggle-room in DuckDuckGo’s claim that they don’t try to second-guess your search terms. Google has the same problem with a verbatim that is-not-really-verbatim.
There’s no sort-by-date filter on the search results, and adding the search modifier sort:date to the search causes a chained-URLs search to totally fail.
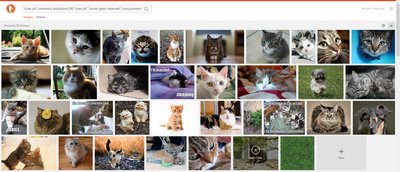
Sadly a list of chained URLs just doesn’t work with DuckDuckGo’s Image Search. For instance, a searcher can’t constrain Image Search thus…
"cute cat" site:flickr.com,deviantart.com,commons.wikimedia.org
When looking for Creative Commons images using DuckDuckGo Image Search a better strategy is probably simply to dispense with the URL chain and use this…
"cute cat" "some rights reserved" OR "cute cat" commons attribution -noncommercial
This will still pick up “noncommercial” CC pictures on Flickr (since Flickr obfuscates the picture’s license behind a “some rights reserved” generality), but at least you’d be headed in the right direction. Note that it seems that DuckDuckGo only lets you use a single minus sign to knock out one keyword from the search, and it has to be at the end of the search to work.
A “Region” filter doesn’t appear to work on Image Search. You can’t just see the “cute cats” of Japan, for instance.