The browser problem I described yesterday is fixed.
As a test sample, consistently utterly un-reachable sites in Opera were…
www.majorgeeks.com
www.etools.ch/
www.davidrevoy.com/blog
All loaded perfectly fine and instantly in the Pale Moon Firefox-based browser.
One clear possible cause I found was LetsEncrypt changing its root site certificates, which are used by way too many (20%?) of the world’s smaller website servers…
DST Root CA X3 will expire on September 30, 2021. That means those older devices that don’t trust ISRG Root X1 will start getting certificate warnings when visiting sites that use Let’s Encrypt certificates.
The timing was right. The systems affected were right. The reason for the Chrome vs. Firefox strangeness was right…
Browsers (Chrome, Safari, Edge, Opera) generally trust the same root certificates as the operating system they are running on. Firefox is the exception: it has its own root store.
Thanks to ‘GGG’, who got it right. He had exactly the same problem as me, Chrome (Brave) not working, Firefox working fine. He traced the broken sites to their use of LetsEncrypt root SSL certificates. This led me to the server techie Gunter Born in Germany warning of the same problems a little in advance and describing them in detail. Apparently the certificates are free and thus are widely used by smaller sites. It’s the world’s largest certificate authority. Seriously. The world’s largest certificate authority suddenly revokes its 300-million+ key server certificates and effectively breaks 20% of the Web and… the media don’t tell anyone in advance? So far as I can see only a few gadget sites and some Indian sites gave a few hours warning.
Anyway, assuming rogue SSL certificates rather than iffy DNS servers was the actual problem, as now seemed very likely… how to fix it?
The solution: You need to manually add fresher certificates. Do as the Tech Journal explains in the new page for the DST Root CA X3 Certificate Expiration Problems and Fix. There Stephen Wagner has kindly dug up the links to the new fresh certificates.
 The guy who saved the world.
The guy who saved the world.
You will need a Firefox or Pale Moon browser to get them, as LetsEncrypt’s problem is blocking LetsEncrypt from itself (durh…). Some Windows users will need to choose the .DER rather than the .PEM version of the certificates. Best to get them all and see which version your Windows recognises and adds an icon to.
Once downloaded you need to double-click them and for each one a Windows Certificate import Wizard will launch. Install it to the correct folder….
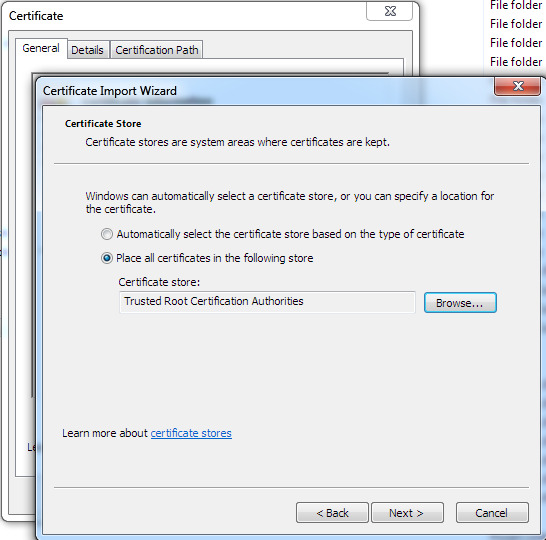
Don’t just accept the Windows defaults (could install anywhere…), but guide each certificate to its correct folder. isrgrootx1.der and isrg-root-x2.der go in the “Trusted Root…” and lets-encrypt-r3.der goes in the “Intermediate…”. Intermediate seems just as important as the others, so don’t skip it. There appears to be no need to delete the old defunct certificates, although browser access seemed to speed up a bit when I hard-deleted the Sept 2021 certs from “Trusted Root…” and “Intermediate…”.
Now when you close and re-launch your Chrome-based browser, and after a pause of perhaps 12-20 seconds for each previously blocked site, the problem should be fixed. It was for me. I assume the one-time pause is for the browser to re-cache the page.
I did not need to re-boot Windows for this fix to ‘take’. The Windows-savvy will be able to type MMC at the Windows Start menu and then load a Snap-in to see new certificates and their dates…
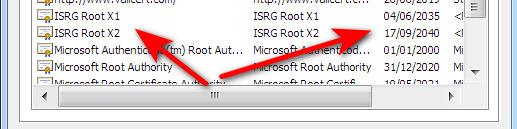
This is also the way you delete the old ones, which cannot be done via Settings | Security | Proxy in Chrome/Opera…

Update: According the Linux Addicts the problem briefly took out Amazon Web Services, Shopify and The Guardian. The Daily Swig adds Google Cloud, Microsoft Azure, and many others.
