Google Search Education
16 Monday Mar 2015
Posted in JURN's Google watch

16 Monday Mar 2015
Posted in JURN's Google watch
01 Sunday Mar 2015
Posted in JURN's Google watch
What if Google Search could demote websites containing a large number of incorrect facts?
17 Wednesday Dec 2014
Posted in JURN's Google watch, Spotted in the news
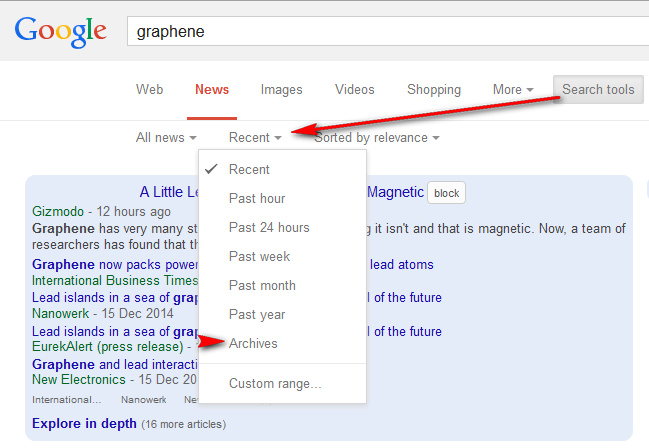
The Google News team has re-enabled the lost archives feature, for searching newspaper archives as far back as 2003…
Great news — we’ve re-enabled archives search! Our team listened to all your feedback you left here in the forum, and was hard at work to bring you an even better archive experience. From all the posts we received, we heard loud and clear how important these archives are to our users. You can now go digging back in time to 2003. Search on :)”
17 Monday Nov 2014
Posted in JURN's Google watch, Spotted in the news
Kevin Kelly at the Edge…
In a curious way, Google is all about answers [and] answers are becoming cheap; they’re almost free, and I think what becomes scarce in this kind of place that we’re headed to [in the future] is questions, a really good question, because a really good question can unleash new questions. In a certain sense what becomes really valuable in a world running under Google’s reign, are great questions…”
16 Sunday Nov 2014
Posted in JURN tips and tricks, JURN's Google watch
This post is for those who’ve recently lost the capability to have their Google Search results look like this in Firefox and a widescreen PC monitor…

Greasemonkey and GoogleMonkeyR are required to do this. They are still working fine together for me, with a few new versions installed…
1. Update Greasemonkey to 2.3 (29th Oct 2014) and GoogleMonkeyR to 1.7.2.
2. Access Google Search via the following URL, which has a parameter that limits search results to 15 per page…
https://www.google.com/webhp?hl=en&complete=0&tbo=1&num=15&tbs=li:1
15 results fit nicely into three columns, the three columns being set up in GoogleMonkeyR Preferences (which is the cog-wheel that appears top-right, once you make a Google search).
3. Hide Google’s “Searches related to …” element on the Google Search results page. You can do this easily in GoogleMonkeyR Preferences. This div needs to be hidden, because otherwise it sits awkwardly between you and the numbered links that lead to the subsequent results pages.
If that doesn’t work for you, then you can do Step 3 with the popular AdBlock Plus add-on (right-click on “”Searches related to …””, ‘Inspect Element’, highlight whole ‘extrares’ element, click on red AdblockPlus icon, and block it on Google.com). Once you’ve learned how to hide page elements like this with AdBlock Plus you can use it on other sites, for instance hiding the sports section or the tacky video sidebars on newspaper websites.
07 Friday Nov 2014
Posted in JURN's Google watch, Spotted in the news
Google Scholar developer Anurag Acharya talks to Nature about the search engine’s future…
the next big thing we would like to do is to get you the articles that you need, but that you don’t know to search for. Can we make serendipity easier? [but] I don’t know how we will make this happen. […] I don’t think getting our users to ‘train’ a recommendations model will work”
18 Monday Aug 2014
Posted in JURN's Google watch
This is interesting. My search for Lovecraft / sort-by-date on JURN gave this result on the first page…

It’s from the latest issue of The Fossil, the journal for the historians of the amateur journalism movement, which is served up as a single PDF with many articles in it. What’s interesting from an academic search perspective is how Google has successfully plucked an article from deep inside the PDF, and yet been able to shown it as a discreet link with the correct title. The opening article in this issue also references H.P. Lovecraft, but it’s tangential since that article is a wider one on the United Amateur Press Association. The main Lovecraft article in the issue is indeed David Goudsward’s “A Visit to Haverhill”, although the topic is not indicated in its title. So it seems Google now has the (new?) ability to pluck a relevant article title out of a longer scholarly PDF, and to present its title in search results as if it were a discreet article. A nice addition to JURN’s capabilities, if such results can be served consistently.
17 Thursday Jul 2014
Posted in JURN's Google watch
Google has removed its filter that enabled search of discussion forums, Usenet groups, Google+ groups (all six of them that are still active… heh), etc.
19 Thursday Jun 2014
Posted in JURN's Google watch, Ooops!
“The dark side of open access in Google and Google Scholar: the case of Latin-American repositories”…
“the [study of the] presence and visibility of [a total of 137] Latin American repositories in Google and Google Scholar […] indicate[s] that the indexing ratio is low in Google, and virtually nonexistent in Google Scholar [with] a complete lack of correspondence between the repository records and the data produced by these two search tools.”
JURN is doing much better, in that regard, with a little help from Red Federada des Repositorios (which is comprehensively indexed by the main Google) and the general ‘open everything’ attitude to publishing scholarship in South America.
05 Thursday Jun 2014
The Court of Justice of the European Union (CJEU) declared today that UK and European Internet users are not acting illegally when simply browsing copyrighted material online.
The equivalent of the USA’s Supreme Court established that users engaged in “Temporary acts of reproduction … which are transient or incidental” (Article 5.1 of the EU Copyright Directive) — such as files automatically copied to a Web browser’s temporary cache and displayed on screen — must not be considered to be making illegal copies. This ruling now applies throughout the UK and Europe.
Earlier this year the EU ruled that hyperlinking to public content is not illegal, and this new ruling seems like the other side of that coin.