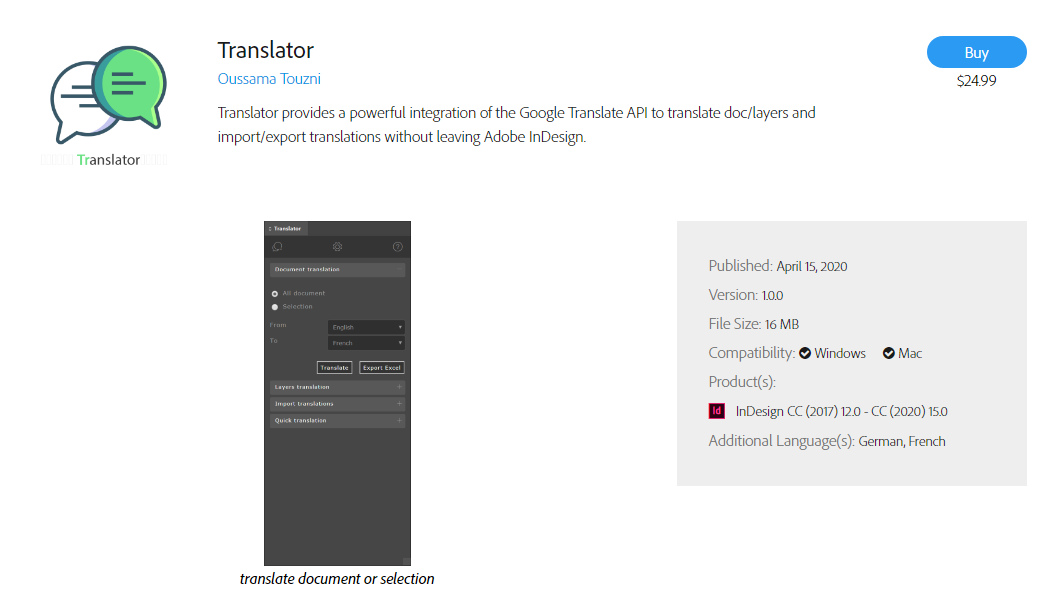
A new $25 Translator integrates Google Translate into Adobe InDesign, Adobe’s PDF editing DTP software. An API key with Google Translate is needed, though.
Another recent third-party option for InDesign editing of PDFs is Translate from Id-Extras, which appears to be promisingly low-cost. It appears from my related searches that, rather surprisingly, that there’s no such thing as an Official Adobe PDF Translator plugin. You might have thought Adobe would have been onto that years ago, and made a small fortune for their shareholders off it. Nor has Microsoft slotted Bing Translator into Microsoft Publisher.
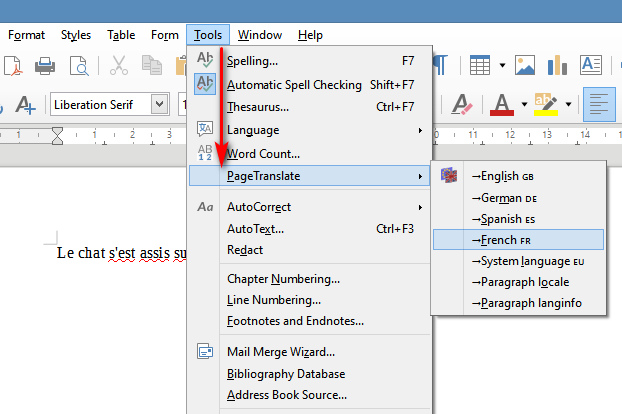
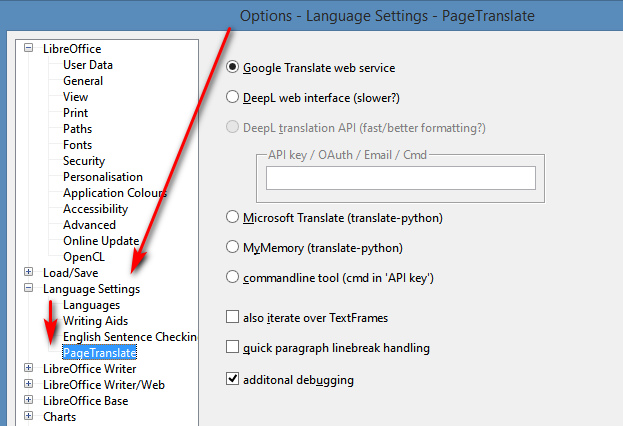
Spotting these made me wonder what was similar and available free for LibreOffice, the free Office suite. I find that “working in 2020” is the free PageTranslate. Install of plugin/extensions in LibreOffice is not manual, but done via Tools | Extension Manager. Once installed, this shows up under Tools | Page Translate…
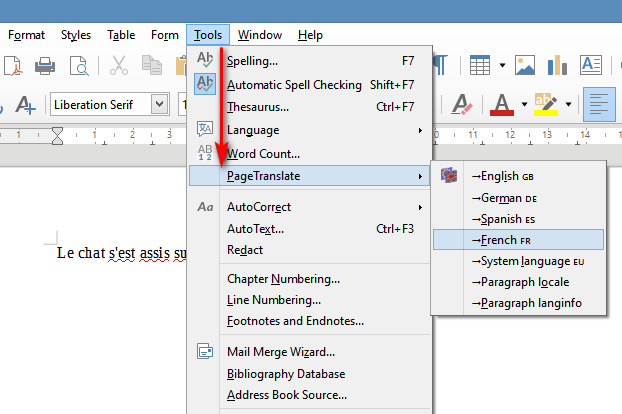
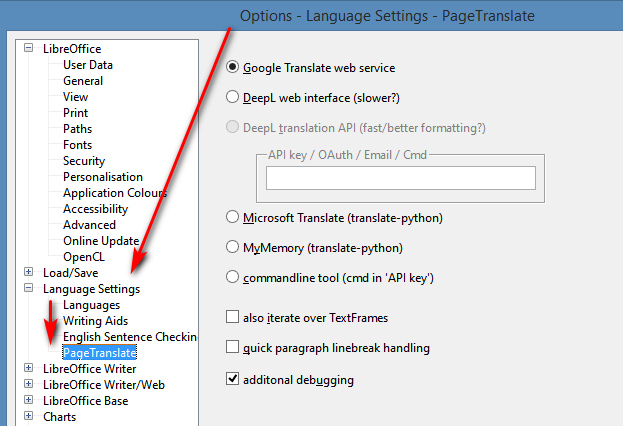
Supported is inline ‘translate and replace’ of English to German, Spanish, French. It works fine in doing this, hooking into Google Translate and allowing both full document translation and translation of “selected and highlighted” text. No API key or other log-on is needed for Google Translate, though you can switch it over to other services that do require keys or logins or suchlike. Its provider settings are found under Options | Language…
Obviously then, if one could rig up a reliable way to convert a PDF to Word, and then translate in place (‘inline’), that would be a useful thing to have on a desktop PC. Especially for those that have slow Internet uplinks, and for whom sending a 80Mb PDF up to the Cloud for translation might take an hour. But I’ve yet to find a reliable freeware for the Windows desktop that offers “PDF to Word, and retain layout 100%”. LibreOffice’s Draw component claims to import PDF, but while it may be adequate for the layout of a plain academic journal it makes an utter hash of the layouts of magazines. This is the sort of layout I’m talking about…

You can see how fiddly it might be to individually copy-paste each block of text to Google Translate, and how easy it would then be to lose track of what bit came from which part of the page. The ideal here would be that some as-yet-unmade software would identify each block of text and its co-ordinates on the page, the text in each would be copied (by OCR if needed) and auto-translated, each text block would be erased then filled with its translated text.
So, until that happy moment it’s back to PDF to Word… and the best genuine conversion freeware I’ve found and tested so far is Nemo PDF to Word 4.0, which is a good try — but does not capture the layouts and font styling 100% on my test PDFs. Maybe 80%, and the remaining messiness may be largely due to font substitution. Which is a problem on my side, not on Nemo’s — my PCs simply lacks the snazzy fonts that the magazine designers were using for their PDF.
There are of course Cloud services and three or four bits of paid software that claim to auto-translate a PDF while retaining 100% layout fidelity, but they all appear to be Cloudy and limited unless you pay. Curiously, none of the ones I’ve looked at offer a few before-and-after “sample conversion” PDFs, by which to judge their wares. Various names include SYSTRAN PDF Translator ($279), Babylon Pro (subscription), Multilizer ($40?) and couple of others. Multilizer does have what is effectively a demo, though. These are at the consumer and small-business level, and I find they are not to be likened to the fiendishly complex pro-translator software suites such as MemoQ and Trados Studio, the latter being designed for translation professionals who have accounts with high-end machine-translation services to assist in their laborious daily work.
One interesting bit of desktop Windows freeware found was Lingoes, but judging by my tests it no longer works in terms of calling in Google Translate. Google tightened up on access a few years back, and it appears to have left several such software makers high and dry. I’d be interested to know if there are still ways to get Lingoes working in 2020, as it otherwise seems be a free alternative to the paid Babylon Pro. Possibly API keys are needed, even for Google Translate?
Finally, I also see that Foxit PDF has just introduced a “Translate PDFs into other languages” free service for those signed up to its Foxit Cloud (also free). No screenshots are included on the blog post, though, so I assume the translation probably “appears” in a sidebar rather than replacing the original text inline in the way that Project Naptha does it.
The free and still-working Project Naptha is exemplary in showing how inline “OCR, translate, erase to white space, paste in translation” should be done. But it can only do English to other languages. Give it a block of text in French, German or Italian and it’s kaput. If someone out there wants to be a major philanthropist to the world, getting Project Naptha able to work with text other than English would be a fine project to fund. The secret to that appears to be getting the free Tesseract OCR engine to work with text other than English.
Update, September 2021: the solution is probably an exact HTML5 conversion…
1) QuarkXpress 2021 and its perfect ‘what you see is what you get’ HTML5 output from PDFs. Save the PDF to HTML5 with QuarkXPress, upload it to the live Web, point Google Translate at it. The layout should retained while the text is translated in-place. Quark can be had for £180 on a perpetual licence and (unlike its rival InDesign) needs no expensive subscription plugin to the WYSIWYG HTML5 output. There may possibly be translation plugins for Quark.
2) An online PDF-HTML5 service such as IDR Solutions.
Both would leave you with the problem of getting the HTML5 uploaded to a live rented webspace, which not everyone has access to.