A curious problem has developed persistently in recent days, for users of Chrome and Edge browser… but not for Firefox / Pale Moon. Evidently the problem is now shared by others as well as myself.
While browsing a site/page fails to respond to the Chrome browser, but springs instantly into action for Firefox or Pale Moon (based on Firefox). In the Chrome-based Opera you get…
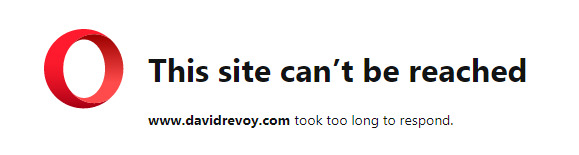
This site can’t be reached. [URL] took too long to respond.
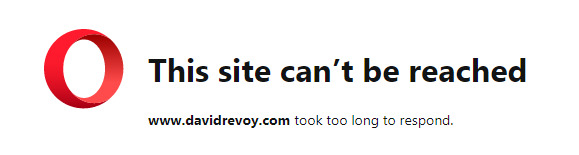
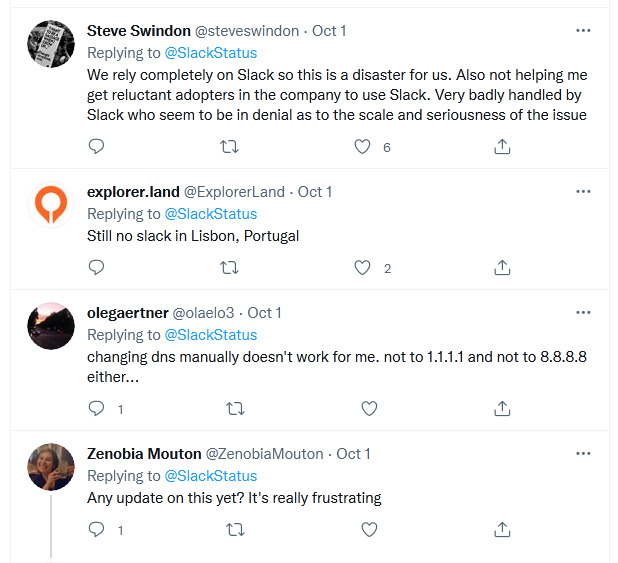
Doesn’t appear to affect the mega-sites like YouTube or WordPress. Sometimes there is a 20-30 second delay in reaching a mid-ranking site, and often nothing at all from smaller sites or certain known recalcitrant mid-ranking sites (e.g. Stack Overflow, GreasyFork). Slack also seems to be badly affected, though that doesn’t affect me…
The problem appears to be cross OS, as I’m on Windows and this other guy (linked above) is on Linux. I have the same symptoms as he has: Chrome often gives this error while Pale Moon (Firefox) is totally fine. The problem occurs even if you are using a DNS server other than that of your ISP. For instance in Opera, it’s possible to select from a number of DNS servers. They all exhibit the same problem. Other fixes tried include:
* Changing the Windows IVP4 DNS to another (9.9.9.9, 8.8.8.8, 1.1.1.1) makes no difference either.
* Running with all browser extensions and scripts off also makes no difference.
* Visiting the page in ‘Incognito mode’ makes no difference.
* Modem reset makes no difference.
* PC reboot makes no difference.
* I don’t have proxies configured.
My first guess was some iffy under-the-hood Chrome update, perhaps some new and imperfect query being made to the some local and rather sluggish and partial DNS cache. Linux-guy’s claimed solution thinks along these lines and he suggests flushing your local DNS, which on Windows is:
1. Start menu.
2. Run.
3. Run dialog box, type…
4. ipconfig /flushdns
5. Confirm. A DOS-box window should flash up for a microsecond, the DNS cache is flushed, and the Run box exits.
Works as described above, but this didn’t cure the problem for me.
Nor did clearing the internal Chrome DNS cache (who knew?) and restarting the browser…
chrome://net-internals/#dns
Then I downgraded the Opera browser, back to Opera 78.0.4093.147 (mid August 2021) with the help of the full offline installer. Still the same problem, and thus it can’t be due to some recently-updated Chrome component.
So… if its not in Windows and not in Chrome, and not due to extensions or other obvious problems… what on earth could it be? It must be some kind of interaction between any DNS server and a Chrome-based browser, even a slightly older one. A problem which Pale Moon/Firefox is not affected by, and which has only recently started in the last few days. It can vary between DNS servers, some loading one page and not the other and visa versa.
One odd thing is that if you click hard and long and quick enough to load such a jammed page, like 50 times, it will often eventually load. This is repeatable. It’s like there’s a ‘black hole’ somewhere along the route, for smaller and mid-ranking sites that need DNS lookup, and eventually the system will ‘get the message’ and use an alternative route. I wonder in DNS servers have been ‘split’ in three and now have different sub-databases for top, middle and lower-ranking sites? And that the low-ranking databases sometimes power down their disks when not being called? That might explain it. The disks could need time to power up. But surely they would be modern always-on SSD’s and not old mechanical hard-drives?
Why Firefox / Pale Moon is unaffected I have no idea. But it is. I’ve been unable to discover if it uses any special DNS routing. Only that Pale Moon has no support for ‘DNS over HTTPS’.
So the temporary solution is then:
1. Open the Pale Moon browser, which has no such problems, and keep it open.
2. Install Andy Portmen’s “Open in Pale Moon” extension in Opera or Chrome.
3. Pin “Open in Pale Moon” button to your bookmarks bar.
4. Launch any recalcitrant page in Pale Moon (Firefox). This browser is already open so it will load instantly, and the supposedly ‘un-findable’ page will also load instantly.
Sadly the above only works once Opera has actually received the “This site can’t be reached. [URL] took too long to respond.” message. If you pass the URL over to Pale Moon while the browser is still waiting (and waiting and waiting…) for a DNS server, you get nothing in Pale Moon. You can however go back and right-click on the original hyperlink and “Open in Pale Moon” that way.
You can also switch your RSS reader to open pages externally in Pale Moon / Firefox.
Update: This, at first glance, seems to explain the difference between the browsers…
1. “Chrome uses DNS prefetching to speed up website lookups”
2. DNS pre-fetch is off by default in Pale Moon… “DNS prefetching disabled by default to prevent router hangups”.
Checking the value on about:config / network.dns.disablePrefetch assures that it is indeed off in Pale Moon.
In Chrome/Opera this is now called “Preload pages for faster browsing and searching”, and again it is turned off for Opera. The uBlock Origin addon forces it off.
So, despite sounding plausible, the above can’t be the explanation for the problem.
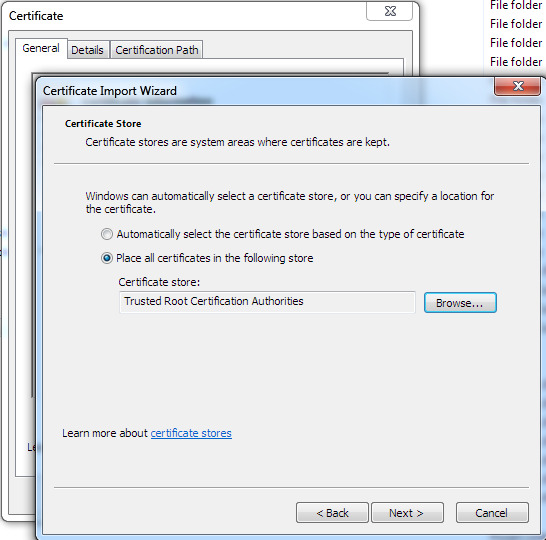
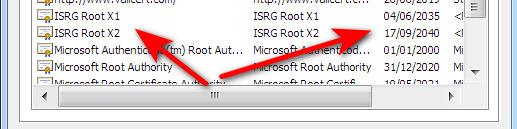
Update: Browser problem fixed: it was LetsEncrypt’s expired root SSL certificates. Install the new ones. Firefox / Pale Moon uses its own SSL certificate store, which was why it was unaffected.