British Journal for Military History (The British Commission for Military History)
Added to JURN
29 Sunday Oct 2017
Posted in New titles added to JURN

29 Sunday Oct 2017
Posted in New titles added to JURN
British Journal for Military History (The British Commission for Military History)
28 Saturday Oct 2017
Posted in Ecology additions, New titles added to JURN
Journal of Daylighting (architecture, place design)
Joelho : journal of architectural culture
Plato Journal (International Plato Society, mirrored here)
Transactions of the International Society for Music Information Retrieval (forthcoming)
27 Friday Oct 2017
Posted in Spotted in the news
Open Content on JSTOR, a new single-page listing of links to all public-and-open content at JSTOR. 2,260 OA books, monographs and reports. 339 pre-1923 journals. You can also do a title search.
All the early pre-1923 journal content should be found in JURN, via selective indexing which targets the pre-1923 JSTOR mirror on Archive.org. The bulk (possibly all) of the OA books are also found in JURN, via picking up record pages at one of the book publisher catalogues (e.g. RAND Corp., which supplies nearly 1,000 of the JSTOR books) and/or on OA book catalogues such as oapen.org. JURN doesn’t index DOAB, as it’s not needed — its content is all covered elsewhere.
27 Friday Oct 2017
Launched today for Open Access Week, the free Knowable Magazine under CC BY-ND. Access the issue here.
There doesn’t seem to be a portable PDF version, just a tablet-tastic Web site with no RSS feed. I don’t mind the lack of a PDF, but if they want to be in the newsfeeds of influencers then surely someone needs to plug in the RSS module.
23 Monday Oct 2017
Posted in New titles added to JURN
22 Sunday Oct 2017
Posted in Spotted in the news
“Sci-Hub provides access to nearly all scholarly literature” is a new, if misleadingly titled, pre-print at PeerJ Preprints. Mis-titled because it seems to imply to the world that all scholarly literature is behind paywalls, or that all the stuff that matters is behind paywalls. It isn’t, as there’s also Open Access. On this point the body of the article contradicts its own title, in terms of the OA coverage…
“Strikingly, coverage [at Sci-Hub] was substantially higher for articles from closed rather than open-access journals (85.2% versus 49.1%).”
So only 49.1% for OA. I’d guess that’s mainly because less people need to plug a DOI into Sci-Hub to get an OA article.
However the idea that 49.1% of “all” OA articles are in Sci-Hub turns out to be very questionable. Because that 49.1% amounts, according to the article, to a piffling “1.4m” articles from 2,650 OA journals.
The whole of OA journal output to date cannot possibly fit into a mere 2.8m articles. For instance, CORE alone has 5m full-text OA papers, according to their February 2017 blog post….
“CORE is thrilled to announce that it currently provides 5 million open access full-text papers.”
And that’s after CORE’s great difficulties in successfully finding and harvesting full-text (running at around 30%, last I heard) from cantankerous repositories. (Update: At Dec 2017 CORE is claiming to locally host 9m in “research outputs” and “full text articles”, inc. 1.8m articles extracted from Elsevier, Springer, Frontiers and PLoS).
Consider also that the DOAJ currently lists just over 10,000 OA journals, even after its recent/ongoing clean-up of titles. DOAJ made 2.5m articles searchable in full-text at 2016, and its full-text holdings hardly even scratch the surface of the contents of DOAJ journals.
Given numbers like these and others, bloggers and journalists should be wary of glancing at this new PeerJ Preprints article and making claims such as: ‘Sci-Hub shown to provide access to nearly half of all OA articles!’
How to explain the mis-match? It appears to be a result of the article’s authors using a database which is very partial in its OA coverage…
“To define the extent of the scholarly literature, we relied on DOIs from the Crossref database”.
After cleaning that haul…
“our catalog consisted of 22,193 journals encompassing 57,074,208 articles. Of these journals, 4,345 (19.6%) were inactive (i.e. no longer publishing articles), and 2,650 were open access (11.9%). Only two journals were inactive and also open access.”
Well now, that last point is interesting in its own right. Is CrossRef throwing out all inactive OA journals? It looks like it. If so, then that seems a bit unfair on OA — but perhaps it’s happening because a CrossRef bot is just automatically tracking the journals in the DOAJ. It’s well known that the DOAJ removes a journal as soon as it ceases or takes a break from publishing, and that would seem to neatly explain the apparent lack of inactive OA journals in CrossRef.
(If that’s the case then I’d also suspect CrossRef may not even be tracking all of the DOAJ: since the journals of ‘the top 10 publishers’ in the DOAJ currently stand at 2,282 OA journal titles. Add a few worthy niche publishers and ‘learned association’ titles, and I’d be willing to bet that CrossRef’s 2,650 OA total would be matched fairly neatly. CrossRef’s title .XLS is here, if anyone cares to do a more precise tally against the DOAJ’s .XLS and then sort the results by publisher).
Which means Sci-Hub is still a long way, probably a very long way (15%?), from useful coverage of all OA journal articles. And it may never offer the claimed… “access to nearly all scholarly literature”. Partly because pirates have little or no interest in pirating ‘free’, and indeed usually take professional pride in shunning ‘free’. Even if they were aiming to pro-actively include OA, neither Sci-Hub or LibGen would be able to provide the public with Google’s speed, relevancy ranking, up-time, traffic management etc. Nor could they remove dead links in the same speedy way as Google does — and I doubt they want to try to mirror the entire OA corpus locally (although they might harvest and ingest things like the CORE full-text, fairly easily). More likely that they will start to detect a DOI request as being OA, and then bounce the user to the public full-text without re-hosting it themselves. In which case I don’t see a Sci-Hub/LibGen combo becoming “the one box to rule them all”.
Which isn’t to say that there won’t one day be some whizzy Web browser addon that provides all sorts of sophisticated automated overlays and injections into your Google Search results, far beyond a basic “article has DOI, look it up on Sci-Hub” button for those too lazy to do a manual copy/paste lookup. In which case it might be possible to approximate a melding of Google Search and Sci-Hub on a single page of results.
17 Tuesday Oct 2017
Posted in Spotted in the news
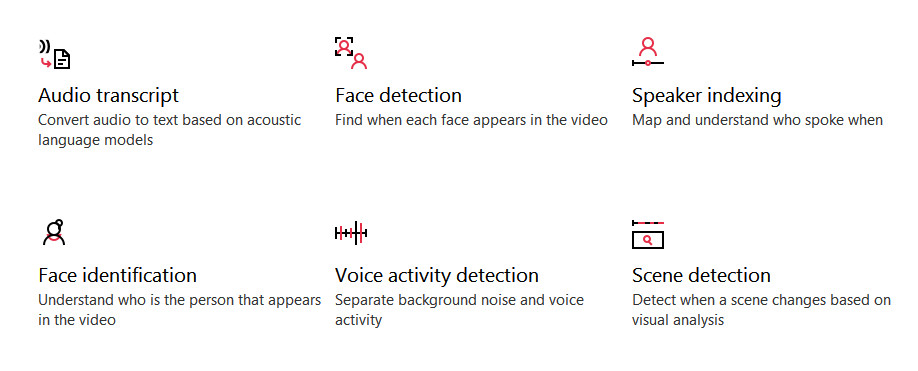
It’s not yet likely to replace your human podcast transcriber on Fivver.com etc, but it’s headed in that direction. Judging by the high accuracy that Google’s automatic YouTube subtitling can achieve for spoken-voice, it seems Microsoft might get to near-human accuracy in a few years if not sooner.
12 Thursday Oct 2017
Posted in Open Access publishing, Spotted in the news
A possible unwanted side-effect of making PhD theses open access in public repositories, if not actually Creative Commons… image libraries want hefty image reproduction fees…
“consider that your average art history PhD will have dozens, if not perhaps hundreds, of images, then soon even an unpublished PhD can become prohibitively expensive. You want to discuss mid-18th Century portraiture, and show perhaps 50 images? That’ll be £750. You want to turn that PhD into a book? £3,050 please, before you’ve even thought of printing costs. Want to put on a Hogarth exhibition, with a decent catalogue? £8,600. Ouch. And Tate [in the UK] are on the cheaper end of the scale.”
And that’s before many image libraries realise that the PhD might be made public as a PDF, and thus that their digital pictures could be extracted at print-res (pro version of Adobe Acrobat, go: Tools | Document Processing | Export All Images) and then whisked into the public domain by cackling anarchists.
But the image given in the article as an example seems to have already had something similar happen to it. It’s the Tate’s copy of “The Painter and his Pug” (£162, please… the Tate having already taken PhD PDFs in repositories into account, and gouged accordingly). The picture’s now on Wikimedia and gleefully marked as public domain.
Still, that picture is by Hogarth. If you’re writing on someone more obscure or more modern, or don’t have the time or search skills to go burrowing into Hathi and Archive.org, then I can see how the gouging ‘repository-increased’ fees could make it difficult.
And difficult not only for the hapless writer. But also for librarians. Once the PhD is in a repository and is the institution’s responsibility, one suspects that some especially viscous picture libraries may even decide to make a bundle of cash by finding ‘personal use’ images in PhDs and demanding institutional prices for their use. In which case in future might we see PhD PDFs with most of the pictures blanked out, due to a mis-match between the assumed ‘personal use, on the library-shelf only’ licence for the pictures (for instance, Google’s 10m-picture LIFE magazine archive) and the subsequent public and institutional status of the document once it hits the repository? (And does so with or without the permission of the author, increasingly). If so, who is then going to go through and censor? One suspects it’ll be too much trouble for librarians to do that by hand, and too much trouble to figure out what stays and what goes (I assume 100% reliable machine-readable rights tagging is a non-starter, due to the human author in the loop). In which case the university’s risk-averse lawyers would just recommend that some bot should automatically detect and delete all the pictures, or — as with the Digital Library of India books that I’ve seen recently — their contrast would be increased so far that the pictures become almost illegible.
One way an author might get around that is to also provide a search link with keywords and phrases embedded in the URL. Thus my URL, when clicked, searches multiple image search-engines for “The Painter and his Pug” etc with a size of more than 2MB. Of course, readers can do that for themselves, but it would be a nice future-proofing courtesy. Or what about ‘intelligent PDFs’ that do that for you, fetching and embedding the required image on-the-fly from wherever it can be best found? An AI might help with that, and perhaps the link might contain an AI-friendly formula for what the required image should look like (big red splotch here, eyes there, etc) to ensure that the correct one is fetched.
11 Wednesday Oct 2017
Posted in Spotted in the news
From Brewster Kahle at the Internet Archive (archive.org):
“The Internet Archive is now leveraging a little known, and perhaps never used, provision of US copyright law, Section 108h, which allows libraries to scan and make available materials published 1923 to 1941 if they are not being actively sold. … Today we announce the “Sonny Bono Memorial Collection” containing the first books [67 at present] to be liberated. Anyone can download, read, and enjoy these works that have been long out of print. We will add another 10,000 books and other works in the near future … as we automate.”
Which doesn’t mean they can be republished commercially or re-used. For many years now it’s not been safe to assume a starting point of “it’s on archive.org, therefore I can probably re-distribute it”. But still, the new tranches of —1941 books will be very useful for scholars.
09 Monday Oct 2017
Posted in Spotted in the news
“Facebook is going to require ads that are targeted to people based on ‘politics, religion, ethnicity or social issues’ to be manually reviewed before they go live'” … “expects the new policy to slow down the launch of new ad campaigns”.
Facebook runs adverts? Never see ’em, as I run AdBlock Plus and F.B. Purity.
{kind=link}