
Internet Archive Scholar, formerly the Fat Cat project, now live and purring. Full-marks for having that rarest of sidebar search-filters, “OA”, though “Fulltext” is presumably broader and thus the one most likely to be used most. It’s also great to see there’s now a keyword-based way to search across all those microfilm journal runs that Archive.org has been uploading recently.
I wouldn’t have used the open ISSN ROAD as a source, nor visually implied that it’s a possible quality-marker. But at least it’s being balanced against the more rigorous DOAJ, and there’s a yes/no flag for both services on the article’s record-page…
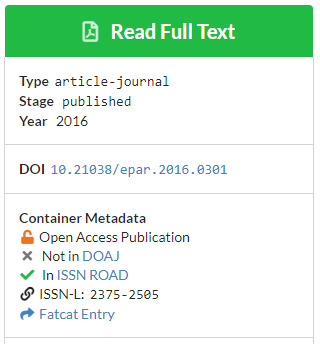
It’s good that the “Read full-text” button goes to a PDF copy at the WayBack Machine, and yet there is also a live link on the record-page that serves to keep a record of the source URL.
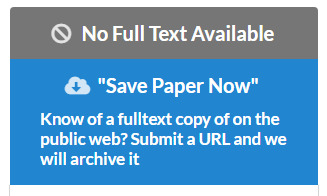
Not all record pages have full-text, though these are very rare. In which case the user is prompted to find and save…
Unfortunately IA Scholar doesn’t appear to respect “quote marks” in search, which is not ideal for a scholarly search engine. For instance a search for “Creationism” defaults to results for “creation”. Nor can it do Google-y stuff like intitle: or anything similar via the sidebar, though I guess such refinements may be yet to come. Update: the command is: title:
A quick test search for Mongolian folk song suggests it’s not wildly astray in terms of relevance. It’s not being led astray by ‘Song’ as a common Chinese author name, for instance, or mongolism as a genetic disease.
How far will Google Search index the fatcat URL? Will they block it from results in due course, for being too verbose and swamping results? Or just tweak the de-duplication algorithm to suppress it a bit? Well, they’re indexing it for now, and as such it’s been experimentally added to JURN. It may well come out again, but I want to test it for a while. If Google Search fully indexes, that should theoretically then give JURN users a way into all the microfilm journal-runs that Archive.org that has recently been uploading.
Hello! Thanks for trying out this prototype.
I have followed JURN for some time, and have done at least one deep crawl of all the “JURN-indexed” journals for preservation. It would be wonderful to get all this content properly indexed in to fatcat/”Internet Archive Scholar”. One missing piece currently is having ISSN linkage for all of the JURN URLs. Would you be interested in collaborating on adding ISSNs to the JURN directory? If so, we could then add “JURN” as a tag in the interface, both as a quality signal and as a search filter. As a caveat it would likely be some time before our depth of indexing can compete with Google, but we hope to get there eventually.
A contributor started on this here: https://github.com/internetarchive/fatcat/issues/46
A couple other notes:
Regarding exact matches on quoted strings, yes we currently index with stemming. We are looking in to a way to allow both exact or stemmed string matches without increasing the search index size too much. A related issue is having search results not be sensitive to diacritic marks.
It is possible to limit queries to specific fields; the prefix is “title:” not “intitle:”. By default queries are all simple AND queries, so all terms and filters must match, as opposed to an OR query or something more sophisticated like what Google Scholar presumably does.
Hi, many thanks for the response and for your work on FatCat and the new IA Scholar, and also for letting Google Search index the record pages.
>”have done at least one deep crawl of all the “JURN-indexed” journals for preservation.”
Good to hear, though note that the Directory page only covers JURN’s English titles in the arts and humanities. There are many more in JURN that are publishing in languages other than English, and many more in law, defence, emergency services, etc. You might also consider doing the same ingestion for the 800+ titles of JURN’s openECO Directory as well, if you haven’t already done so… https://jurnsearch.wordpress.com/titles-indexed-ecology-related/
>”It would be wonderful to get all this content properly indexed into fatcat/”Internet Archive Scholar”. One missing piece currently is having ISSN linkage for all of the JURN URLs. Would you be interested in collaborating on adding ISSNs to the JURN directory?”
That would be interesting possibility, albeit quite a lot of unpaid voluntary work for me. The first hurdle is that JURN’s English-language Directory is not in Excel, only in HTML. But it would be relatively easy to comma-separate and thus get it into an Excel spreadsheet. Then I would need to find an Excel plugin that does the following:
1) Excel downloads the page from each URL;
2) it parses the HTML it obtains, to find only value “X”;
3) and it then appends “X” to the end of the starting URL cell.
Do you know of such an automation tool, either in Excel or from some other source? It can be done if the target is an ecommerce site that uses consistent tables and class names, e.g. http://automatetheweb.net/reddit-how-to-extract-data-from-html-into-excel/ – but I would need something more flexible that that, that could regex the HTML for “ISSN:” and fancy designer-variants such as “i s s n :” and then grab the following 1234-5678 dashed number.
I don’t see a handy Sobolsoft solution for doing that, and I would need that sort of Windows desktop software with a GUI. But such a plugin would do most of the grunt-work, and then it would be just a matter of filling in the gaps by hand.
Of course arts and humanities journals do not all have ISSNs. Also, unlike the DOAJ, JURN is happy to index ceased journals that keep their back-issues available to the public. Some of these do not have ISSNs due to their age. There would therefore necessarily be some gaps in ISSN coverage, and especially on small technical newsletters, bulletins and the like. e.g. https://williamstownart.org/technical-bulletins/ I’m uncertain if such gaps would disqualify a partly ISSN’d Directory from consideration?
>”We are looking in to a way to allow both exact or stemmed string matches without increasing the search index size too much.” It is possible to limit queries to specific fields; the prefix is “title:” not “intitle:”.
That’s great to know, many thanks.
> Good to hear, though note that the Directory page only covers JURN’s English titles in the arts and humanities. […]
Ah! Is it possible to get a list of all the URLs? Eg, an export from Google?
> You might also consider doing the same ingestion for the 800+ titles of JURN’s openECO Directory as well, if you haven’t already done so…
Yes, I included openEco also, at the time (August 2019)
> That would be interesting possibility, albeit quite a lot of unpaid voluntary work for me. […]
Here is a tab-separated copy of the JURN directory, extracted from the HTML. I have not verified that the extraction was perfect, but it mostly looks good: https://archive.org/download/jurn-directory/jurn_title_url.2020-10-05.tsv
What I was thinking was to fuzzy-reconcile this against existing ISSN databases using the title, but trying to extract the ISSN from the homepage might work as well. A contributor tried using OpenRefine to reconcile against wikidata.org and got about 990 out of 3311 (at the time). I vaguely hoped we could get 90%+ matches in an automated fashion, and then handle the remainder by hand. For instance, we could create fatcat “containers” (venue/journal/website/etc) for any resources which have no ISSN. We have had a few folks interested in data entry volunteering after our recent blog post, who might be willing to help if we can simplify this task. Not having an ISSN isn’t a blocker from a scope or quality standpoint (the content is actually probably more at-risk and worth preserving), it just helps a lot with automation and de-duplication.
I’m not sure how we could feed this back to you… I could probably write a script to insert ISSNs into your HTML as a one-time thing if you would be interested in having that listed visually.
>”Ah! Is it possible to get a list of all the URLs? e.g., an export from Google?”
No, not the full URL list that drives the CSE. It wouldn’t be very parse-able back to ISSNs/titles anyway, due to the URLs-only format and those are often wild-carded. However the English-language journals in the arts & humanities, and the eco titles are available in their linked directories.
>”Not having an ISSN isn’t a blocker from a scope or quality standpoint (the content is actually probably more at-risk and worth preserving), it just helps a lot with automation and de-duplication.”
Ok, that’s good to know, thanks.
>”trying to extract the ISSN from the homepage might work as well.”
Yes, if one catches the line rather than the number. I guess the ideal would have been to require (20 years ago) all open access publications to include the ISSN and OA status as part of their URL path, but that chance has been lost.
At 2020 I find in test that Sobolsoft’s “Extract Data & Text From Multiple Web Sites Software” can speedily get and parse the HTML and find the ISSN(s) per-URL, and it would greatly speed up a manual hunt for the ISSN on any home-page. But it’s no help with the automatic copying and appending of the ISSN to each starting URL. For that Excel would be needed.
Excel 2016 introduced Power Query and Get & Transform, which can apparently do this sort of thing with an add-in to make it easier… https://analystcave.com/excel-tools/excel-scrape-html-add/
But for my antique Excel 2007 it seems I need to learn about the older “Web query” and “Webrequest” functions, and no-one has a working sample Excel 2007 spreadsheet to offer in that line. The process appears to have favoured data in tables, anyway.
The popular Cloud service Octoparse is no good, as they state their “List of URLs” automation only works if the listed pages all have the same structure.
I suspect then that the best option is just to give the task to the experienced data extractors on Fivver and pay £20. I’ve made an enquiry to a suitable-looking seller, at that price.
There’s some ISSN-parsing regex here that may smooth the way for such transactions… https://libraries.mercer.edu/ursa/bitstream/handle/10898/3687/Chas2016.py
and some sort of ISSN validator here https://commons.apache.org/proper/commons-validator/xref-test/org/apache/commons/validator/routines/ISSNValidatorTest.html
I tried to get some likely Fivver guys interested in an Excel ISSN extractor, but £20 was too little for them. So I did it myself… https://jurnsearch.wordpress.com/2020/10/11/working-excel-spreadsheet-take-a-list-of-home-page-urls-harvest-the-html-extract-a-snippet-of-data-from-each/ The resulting data has now been plugged into JURN’s openECO directory and it being slowly supplemented by manual-lookup, assisted by the Sobolsoft software.
Great! I will take a look at the openECO ISSNs.
I’m not as familiar with the Excel ecosystem. It looks like the Wikidata “Mix’n’match” tool might be applicable, and has been used successfully for some similar journal lists: https://mix-n-match.toolforge.org/#/group/journals