
Ever wonder what a Web page would look like if just the plain HTML were shown, as if it were 1996 again? Ah, but which HTML? There are actually two forms of HTML that reach your browser, and there can be quite a disparity between these two types.
The first is what you see after the raw HTML has been pummelled about by CSS and javascript and the browser’s interpretation. This is often referred to as the ‘DOM’ HTML. This code is what you see and navigate through if you ‘Inspect element’ in your browser, or if you block an element with uBlock’s Element Picker tool.
The second type is the HTML code that gets sent to the browser in the first place, and that original is kept pristine and effectively ‘under’ the Web page. It can be seen via: right-click on page / ‘View source’. This source can then be selected and copied with a Ctrl + A / Ctrl + C keyboard command. Or it can be saved out when you ‘Save page as…’ / ‘Save as HTML only’, and from there you can re-open the saved page in the browser. Some remote CSS, javascript and images may still be called, even then.
A quicker way to ‘see’ this original without its CSS and other ‘remote-code’ flibbertigibbets is to install the add-on disable-HTML in your browser…
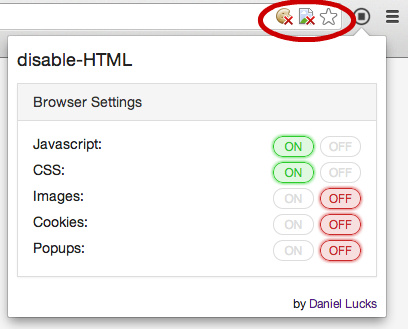
The addon is quite simple to use, and though old still works fine. It was somewhat mis-named, as it can robustly block everything except the HTML of the actual ‘page source’. With CSS and javascript blocked, it appears to be blocking the DOM version of the HTML from emerging from the page source. So what you see displayed, on page re-load, is effectively the page source. As such it can be quite handy for the removal of some types of especially tough and obstreperous CSS-and-javascript -driven overlays, in a situation where you don’t much care about the fancy wrapping and just want the words in a readable and/or copy-able form. Such as on the vile overlays of the unherd.com site.
Pingback: Overlay blockers | News from JURN