
This tutorial and workflow is for those who want to do fairly light and basic web-scraping, of text with live links, using freeware.
You wish to copy blocks of text from the Web to your Windows clipboard, while also retaining hyperlinks as they occurred in the original text. This is an example of what current happens…
On the Web page:
This is the text to be copied.
What usually gets copied to the clipboard:
This is the text to be copied.
Instead, it would be useful to have this copied to the clipboard:
![]()
Why is this needed?
Possibly your target text is a large set of linked search-results, tables-of-contents from journals, or similar dynamic content which contains HTML-coded Web links among the plain text. Your browser’s ‘View Source’ option for the Web page shows you only HTML code that is essentially impenetrable and/or unfathomable spaghetti — while this code can be copied to the clipboard, it is effectively un-usable.
Some possible tools to do this:
I liked the idea and introductory videos of the WebHarvy ($99) Web browser. Basically this is a Chrome browser, but completely geared up for easy data extraction from data-driven Web pages. It also assumes that the average SEO worker needs things kept relatively simple and fast. It’s desktop software with (apparently) no cloud or subscription shackle, but it is somewhat expensive if used only for the small and rare tasks of the sort bloggers and Web cataloguers might want to do. Possibly it would be even more expensive if you needed to regularly buy blocks of proxies to use with it.
At the other end of the spectrum is the free little Copycat browser addon, but I just could not get it to work reliably in Opera, Vivaldi or Chrome. Sometimes it works, sometimes it only gets a few links, sometimes it fails completely. But, if all you need to occasionally capture text with five or six links in it then you might want to take a look. Copycat has the very useful ability to force absolute URL paths in the copied links.
I could find no Windows-native ‘clipboard extender’ that can do this, although Word can paste live ‘blue underlined’ links from the clipboard — so it should be technically possible to code a hypothetical ‘LinkPad’ that does the same but then converts to plain text with HTML coded links.
My selected free tool:
I eventually found something similar to Copycat, but it works. It’s Yoo’s free Copy Markup Markdown. This is a 2019 Chrome browser addon (also works in Opera and presumably in other Chrome-based browsers). I find it can reliably and instantly capture 100 search results to the clipboard in either HTML or Markdown with URLs in place. You may want to tick “allow access to search engine results”, if you plan to run it on major engines etc. Update: it can also just copy the entire page to the clipboard in markdown, no selection needed! It doesn’t however, copy the “Page Source” HTML, only the displayed DOM version of the HTML powering the page. These can be very different things.
Cleaning the results:
Unlike the Copycat addon, it seems the ‘Copy Markup Markdown’ addon can’t force absolute URL paths. Thus, the first thing to check on your clipboard is the link format. If it’s ../data/entry0001.html then you need to add back the absolute Web address. Any text editor like Notepad or Notepad++ can do this. In practice, this problem should only happen on a few sites.
You then need to filter the clipboard text, to retain only the lines you want. For instance…
Each data block looks like:
Unwanted header text.
This is [the hyperlinked] article title.
Author name.
[The hyperlinked] journal title, and date.
Some extra unwanted text.
Snippet.
Oooh, look… social-media buttons! [Link] [Link] [Link] [Link]
Even more unwanted text!
You want this snipped and cleaned to:
Author name.
[The hyperlinked] article title.
[The hyperlinked] journal title, and date.
Notepad++ can do this cleaning, with a set of very complex ‘regex’ queries. But I just couldn’t get even a single one of these to work in any way, either in Replace, Search or Mark mode, with various Search Modes either enabled or disabled. The only one that worked was a really simple one — .*spam.* — which when used in Replace | Replace All, removed all lines containing the knockout keyword. Possibly this simple ‘regex’ could be extended to include more than one keyword.
The fallback, for mere mortals who are not Regex Gods, is a Notepad++ plugin and a script. This takes the opposite approach — marking only the lines you want to copy out, rather than deleting lines. The script is Scott Sumner’s new PythonScript BookmarkHitLineWithLinesBeforeAndAfter.py script. (my backup screenshot). This script hides certain useful but complex ‘regex’ commands, presenting them as a simple user-friendly panel.
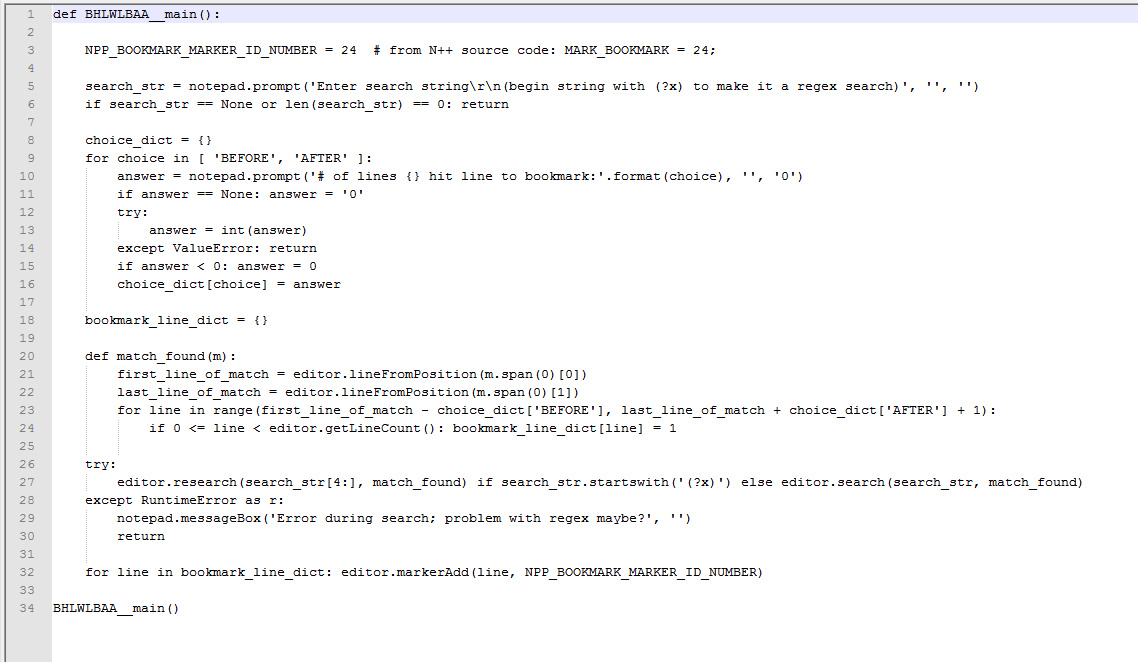{kind=link}
This script does work… but does not work in the current version of Notepad++. Unfortunately the new Notepad++ developers have recently changed the plugin folder structure around, for no great reason that I can see, and in a way that breaks a whole host of former plugins or which make attempted installs of these confusing and frustrating when they fail to show up. The easiest thing to do is bypass all that tedious confusion and fiddly workarounds, and simply install the old 32-bit Notepad++ v5.9 alongside your shiny new 64-bit version. On install of the older 32-bit version, be sure to check ‘Do not use the Appdata folder’ for plugins. Then install the Notepad++ Python Script 1.0.6 32-bit plugin (which works with 5.9, tested), so that you can run scripts in v5.9. Then install Scott Sumner’s new PythonScript BookmarkHitLineWithLinesBeforeAndAfter.py script. Install it to C:\Program Files (x86)\Notepad++\plugins\PythonScript\scripts.
OK, that technical workaround diversion was all very tedious… but now that you have a working useful version of Notepad++ installed and set up, in Notepad++ line filtering is then a simple process.
First, in Notepad++…
Search | Find | ‘Mark’ tab | Tick ‘Bookmark line’.
This adds a temporary placeholder mark alongside lines in the list that contain keyword X…
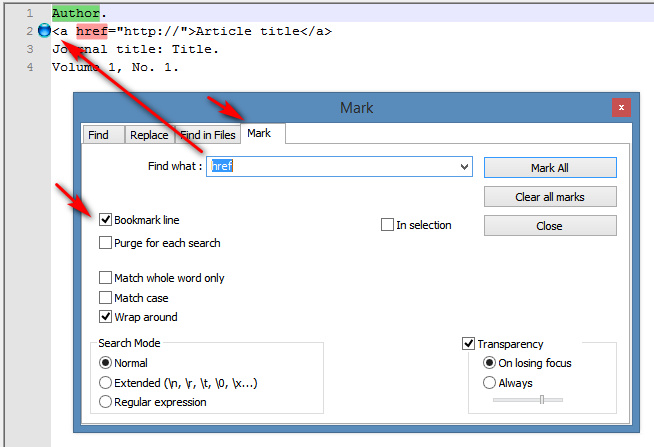
In the case of clipboard text with HTML links, you might want to bookmark lines of text containing ‘href‘. Or lines containing ‘Journal:‘ or ‘Author:‘. Marking these lines can be done cumulatively until you have all your needed lines bookmarked, ready to be auto-extracted into a new list.
Ah… but what if you also need to bookmark lines above and below the hyperlinks? Lines which are unique and have nothing to ‘grab onto’ in terms of keywords? Such as an article’s author name which has no author: marker? You almost certainly have captured such lines in the copy process, and thus the easiest way to mark these is with Scott Sumner’s new PythonScript (linked above). This has the advantage that you can also specify a set number of lines above/below the search hit, lines that also need to be marked. Once installed, Scott’s script is found under Scripts | Python Scripts | Scripts, and works very simply and like any other dialogue. Using it we can mark one line above href, and two lines below…
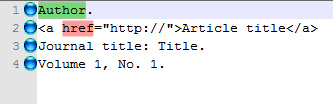
Once you have all your desired lines bookmarked, which should only take a minute, you can then extract these lines natively in Notepad++ via…
Search | Bookmark | ‘Copy Bookmarked lines’ (to the Clipboard).
This whole process can potentially be encapsulated in a macro, if you’re going to be doing it a lot. Perhaps not necessarily with Notepad++’s own macros, which have problems with recording plugins, but perhaps with JitBit or a similar automator. The above has the great advantage that you don’t have to enter or see any regex commands. It all sounds fiendishly complicated, but once everything’s installed and running it’s a relatively simple and fast process.
Re-order and delete lines in data-blocks, in a list?
Scott Sumner’s script can’t skip a line and then mark a slightly later line. Thus the general capture process has likely grabbed some extra lines within the blocks, that you now want to delete. But there may be no keyword in them to the grab onto. For instance…
[The hyperlinked] article title
Random author name
Gibbery wibble
Random journal title, random date
The Gibbery wibble line in each data block needs to be deleted, and yet each instance of Gibbery wibble has different wording. In this case you need either: the freeware List Numberer (quick) to add extra data to enable you to then delete only certain lines; or my recent tutorial on how to use Excel to delete every nth line in a list of data-blocks (slower). The advantage of using Excel is that you can also use this method to re-sort lines within blocks in a long list, for instance to:
Random author name
[The hyperlinked] article title
Random journal title, random date
Alternatives?:
Microsoft Word can, of course, happily retain embedded Web links when copy-pasting from the Web (hyperlinks are underlined in blue, and still clickable, a process familiar to many). But who wants to wrestle with that behemoth and then save to and comb through Microsoft’s bloated HTML output, just to copy a block of text while retaining its embedded links?
Notepad++ will allow you to ‘paste special’ | ‘paste HTML content’, it’s true. But even one simple link gets wrapped in 25 lines of billowing code, and there appears to be no way to tame this. Doing the same with a set of search engine results just gives you a solid wall of impenetrable gibberish.
There are also various ‘HTML table to CSV / Excel’ browser addons, but they require the data to be in an old-school table form on the Web page. Which search and similar dynamic results may not be.
There are plenty of plain ‘link grabber’ addons (LinkClump is probably the best, though slightly tricky to configure for the first time), but all they can grab is the link(s) and title. Not the link + surrounding plain-text lines of content.
There were a couple of ‘xpath based’ extractors (extract page parts based on HTML classes and tags), but in practice I found it’s almost impossible to grab and align page elements within highly complex code. Even with the help of ‘picker’ assistants. I also found an addon that would run regex on pages, Regex Scraper. But for repeating data it’s probably easier to take it to per-line Markdown then run a regex macro on it in Notepad++.
The free ‘data scraper’ SEO addons all look very dodgy to me, and I didn’t trust a single one of them (there are about ten likely-looking ones for Chrome), even when they didn’t try to grab a huge amount of access rights. I also prefer a solution that will still go on working on a desktop PC long after such companies vanish. Using a simple browser addon, Notepad++ and Excel fits that bill. If I had the cash and the regular need, I would look at the $99 WebHarvy (there’s a 14-day free trial). The only problem there seems to be that it would need to be run with proxies, whereas the above solution doesn’t as the content is simply grabbed via copy-paste.