
How to save a multipage Web-book or full set of journal articles to a single PDF file.
Situation: You sometimes encounter full books online, split up into perhaps 300 or more separate HTML Web pages, each containing a bit of text from the book. You wish to re-combine this chopped-up book into a single offline PDF or ebook file, with the bits assembled in the correct order. You might want to do the same with a large journal issue. You need some Windows freeware to solve this, and don’t wish to use cloud/upload services.
Solution: A free Chrome browser plugin, and a Windows freeware utility.
Test book: Minsky’s The Society of Mind from Aurellem, with nearly 300 HTML pages. These are all linked from the main front page, which shows a linked table-of-contents.
Clicking heck!
Step 1. Install Browsec’s Link Klipper – Extract all links browser addon (for Chrome based browsers, inc. Opera) or similar. Run it on your target Web page. Open the resulting plain-text list of extracted URL links, re-order these as needed, and then copy the list of the links you want to the Windows clipboard.
One problem you may encounter here is that the filenames may be obfuscated, as perhaps jj8er4477-j.html rather than Chapter-1.html. But it seems that Link Klipper follows the URLs down in in-HTML sequence, and thus presents them in a list in the same manner. Linkclump is a good alternative browser addon, for those who need precise and manual control of the URL capture, though it is probably a bit fiddly for the first-time user to get working in that manner.
Note that Link Klipper is meant for the SEO crowd, so it can also do Regex and can save to .CSV for sophisticated link-sorting with Microsoft Office Excel.
Step 2. The genuine Windows freeware Weeny Free HTML to PDF Converter 2.0 can then accept Link Klipper’s simple URL list. Just paste it in…
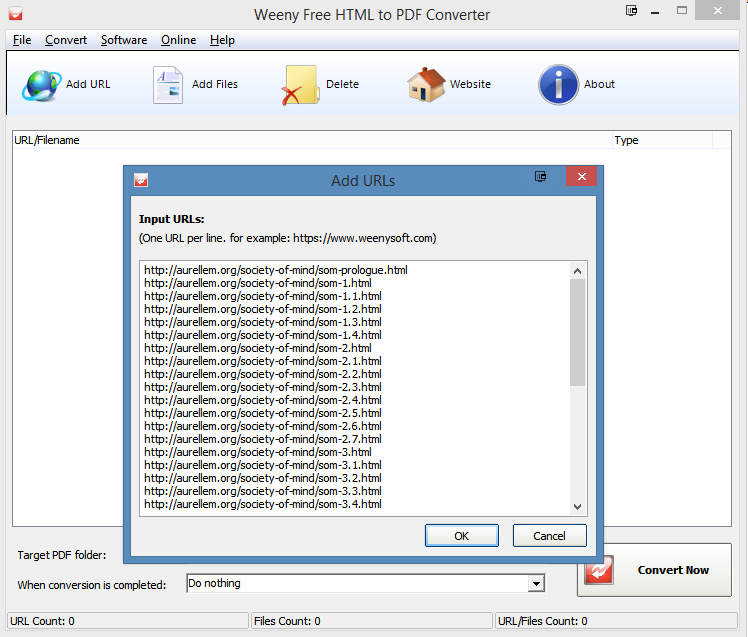
Weeny is very simple to get running and will then go fetch and save each URL in order, outputting a clean PDF for each (as if it had been saved from a good Web browser). There’s no option to select repeating parts of each page to omit, it saves all-or-nothing. It can’t process embedded videos and similar interactive/multimedia elements.
During the saving process Weeny may appear to freeze, showing ‘Not Responding’, if fed hundreds of HTML pages. However, an inspection of the output folder will show that PDFs continue to be converted and dropped into it one-by-one. Thus, even if Weeny seems to choke and crash on 300+ files, it hasn’t done so. Just let it run until it completes.
If the Link Klipper URL list was in the correct sequence, then a sort ‘By Date’ of the resulting PDF files should place the book parts in their correct order, even if the filenames were obfuscated.
We could have downloaded the pages as HTML, but in practice it’s not viable to then join them up. Inevitably, there’s some broken HTML tag somewhere in the combined file, and that causes problems in the text which start to cascade down. PDF is the more robust format.
Step 3. OK, so that’s fairly quickly and easily done. But, oh joy… you’ll now have nearly 300 PDF files, all very nice-looking… but separate! Weeny is sweet software, but not very powerful and thus it doesn’t also join the PDFs together.
If you have the full paid Adobe Acrobat (not the Reader) then you can combine these PDFs very easily (or ‘bind’ them, in Adobe-speak). Acrobat also offers the great benefit of file re-ordering by dragging.
You’re done, and the whole process should have taken ten minutes at most. If the font is not ideal for lengthy reading, the free Calibre can convert the PDF to .RTF or .DOCX for Word, HTML, and various eBook formats.
“But I don’t have the full Adobe Acrobat”:
For those who need freeware for this last step of combining the PDFs, you need to find one that offers a similar ‘re-ordering by dragging’ to Adobe Acrobat. Such freeware is not at all easy to find. Most such Windows utilities are old and use very clunky up/down buttons for re-ordering. That’s not so useful if you have a file number 298 that needs to be moved up to become file 1 — you’re only going to want to do that by dragging, not by clicking a button 297 times. Why might you need to re-order? Because with a big book, you almost certainly got the file order a little wrong, when glancing down and editing the initial URL list in Link Klipper.
Eventually, I found the right sort of free software to do the job. DocuFreezer 3.0 is free for non-commercial use, only adding a non-obtrusive watermark “Created by free version of Docufreezer”. It’s robust and good-looking 2019 software, and it needs Microsoft .NET Framework 4.0 or higher to run (which many Windows users already have).
DocuFreezer can re-sort the imported PDF files ‘By Date’, or by some slightly fiddly dragging (a feature which seems unique among such freeware). It can even OCR the resulting PDF. You just need to remember to tell it to combine and save as a single PDF, and to do the OCR…
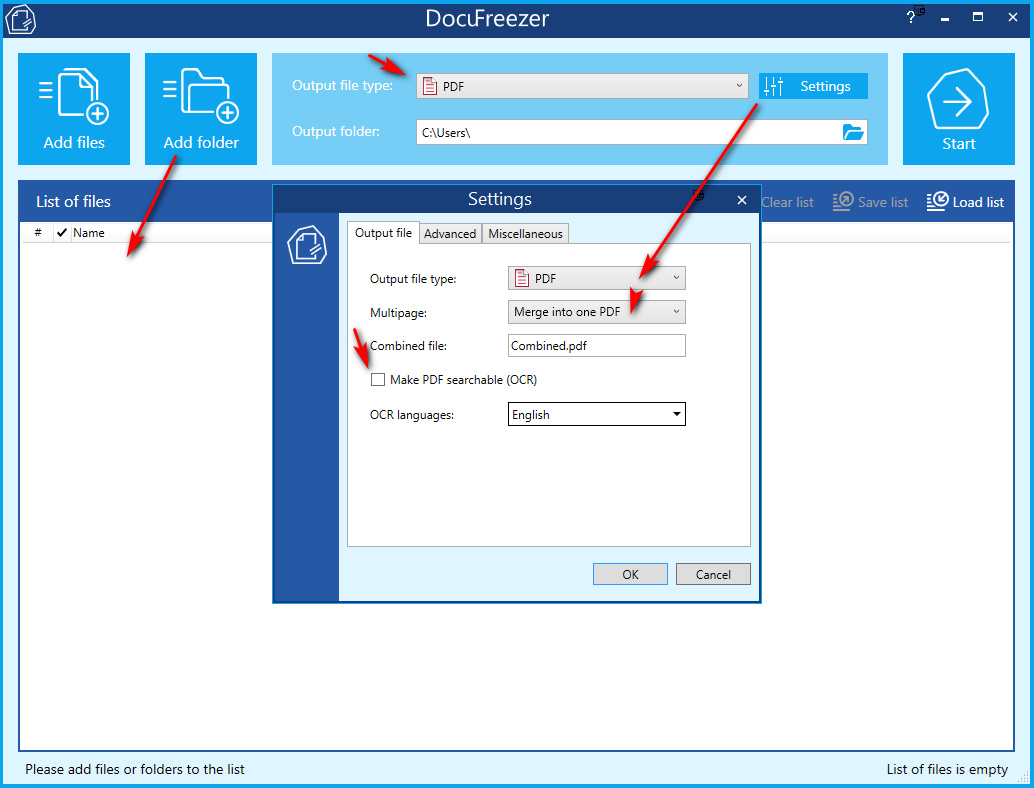
It’s reasonably fast, if you don’t OCR. Removing the watermark, by getting the paid Commercial version, costs $50. Even so, Docufreezer’s free version is no problem if all you want is a personal offline PDF of a ebook for reading — the watermark is quite discreetly placed on the side edge of each page in plain black lettering…

You can also see here that the embedded video, from the original HTML page, was elegantly worked around by Weeny while retaining the page’s images and font styling.
To .CBZ format:
Theoretically one could use this process to then get .JPG files, to compile offline versions of webcomics like Stand Still. Stay Silent., and other primarily visual sequential content. If you have the full Adobe Acrobat then it’s easy to save out the PDFs as big page-image .JPGs in sequence, bundle them into a .ZIP, rename the .ZIP to .CBZ file… and you’re done.
Though you may then encounter a problem in the layout. Unlike mostly-text books, webcomics and other visuals may not fit well on a single portrait-oriented PDF page, without running over. In other words, if you need to scroll down the Web page to see the whole image, then your final PDF page-flow may not be ideal.
In practice, most PDF-to-JPG freeware utilities are not viable in this workflow. I found only a few, and they either contain third-party ‘toolbars’ or just don’t install on modern Windows, or the JPGs they produce are watermarked. They would also need to offer file re-sorting by-dragging, and robust batch processing, and a file mask to rename the .JPG files sequentially — because it’s important for a CBZ to have its filenaming of pages be properly sequential (0001.jpg, 0002.jpg). I’d welcome hearing of such a freeware, but I don’t think it currently exists.
The better option then is simply to read the material online. Or if you really need it offline, then use a free open source website ripper such as HTTrack Website Copier to make a mirror of the website and set to only save the .JPGs to your PC. This assumes that the website doesn’t have traffic surge control or anti-ripper measures in place. But you should really be supporting the comic maker and buying their paid Kindle ebook editions.
“Ooh, does the workflow work on open access journal TOCs?”:
Yes, indeed it does. Not all open/free journals also offer a single-PDF version of the issue (containing all their articles), especially those in a more magazine-like, trade journal, or blog-like format. In such a case, one can run the above quick workflow on the issue’s TOC page, thus quickly providing yourself with a per-issue portable offline single-PDF for your favourite journal in the garden or at the beach. You can then run it through the free Calibre to get it to various ebook formats such as .MOBI (Kindle ereader) and .ePUB.
For a journal issue where PDFs links are already present beside the HTML article links, but there are a great many PDFs, then the browser addon Linkclump is your best option to grab them all.
Clicking heck, that’s a lot of PDFs in an issue! And there’s no single-volume PDF.

You can set up LinkClump to select / open / download all the PDF links (this works even with repository and OJS redirects which use /cgi/), to grab the PDFs for joining with DocuFreezer or some other free desktop PDF joiner. This method is a lot easier than fiddling around with a bulk downloader browser-addon, and picking out the PDFs from a long jumbled list of files. Or you can have LinkClump grab a list of the HTML article URLs for processing to a PDF book, with the above Klipper – Weeny – DocuFreezer workflow.

“My super-mega-combo PDF is too big”:
If your resulting PDF is too large to Send to Kindle (Amazon has as a 50Mb per-file transfer limit, and many people also have very slow uplinks), then there are a couple of PDF shrinkers worth having, from the freeware but rather clunky Free PDF Compressor to the slick and easy $20 PDF Compressor V3 (I like and use the latter a lot).