Another new prodding of Google Scholar, this time from the latest First Monday “Testing Google Scholar bibliographic data: Estimating error rates for Google Scholar citation parsing”…
While data quality is good for journal articles and conference proceedings, books and edited collections are often wrongly described or have incomplete data. We identify a particular problem with material from online repositories [where there appears to be] considerable inhomogeneity in the implementation of data standards [and] a mismatch between repository software and the harvesting protocols employed by Google Scholar.
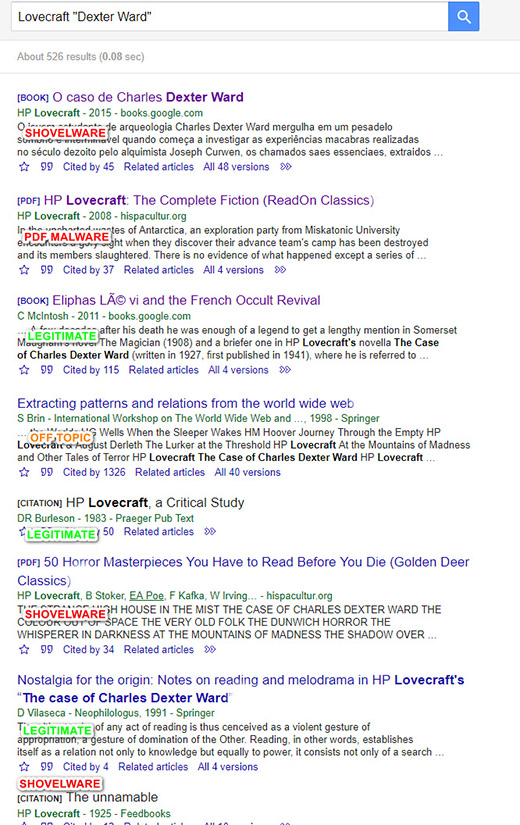
One of Scholar’s other problems is that it includes Google Books results. While 30% of the time its Google Books inclusions can useful, there is no way to exclude Books results. One might want to exclude because Scholar still can’t seem to determine a proper book from a robot-produced shovelware ebook that assembles public-domain content. Scholar has no ‘edition authority’ which states that the Joshi-edited and annotated Penguin Classics edition of H.P. Lovecraft’s “Dexter Ward” is the gold-standard and that it has a text that has been fully corrected of the many textual errors, omissions and editing mistakes of previous decades. Unlike the public-domain shovelware ebooks that flood Amazon and (often) Google Books.
A basic undergraduate level search, for instance, for Lovecraft “Dexter Ward”, demonstrates the problem on the first page. Joshi is nowhere to be seen, and the searcher is hammered by links to shovelware ebooks (or worse), often with citation counts that suggest they are legitimate.