The REF’s decision
11 Friday May 2018
Posted in Spotted in the news

11 Friday May 2018
Posted in Spotted in the news
10 Thursday May 2018
Posted in JURN tips and tricks, Spotted in the news
The free open-source Tesseract OCR 4.0 for Windows (beta, 64-bit), released 14th April 2018.
“The Mannheim University Library uses Tesseract to perform OCR of historical German newspapers. Normally we run Tesseract on Debian GNU Linux, but there was also the need for a Windows version. That’s why we have built a Tesseract installer for Windows.”
The Tesseract engine was apparently originally from Google, in use there at Google Books, but Google made it open source.
Tesseract 4.0 supports OCR in a range of old and ancient letterforms including German blackletter (aka Fraktur, in popular parlance ‘Gothic’), but these need to selectively enabled at install…
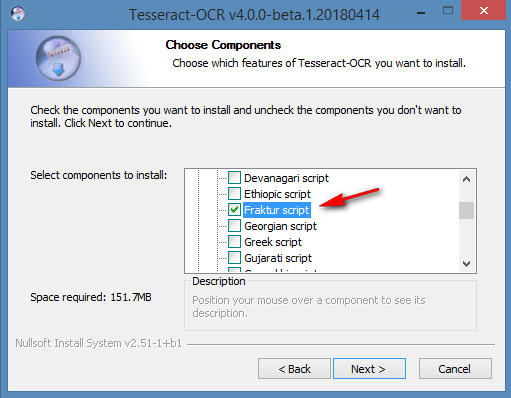
Once installed there are a few Windows GUI front-ends to choose from, with which to operate Tesseract. gImageReader is 64-bit Windows and current. On their forums I found a gImageReader beta version that is newly-compiled for Tesseract 4.0 beta. That needs to be launched in Windows Administrator mode, and then it also seems to require a Fraktur download, in order to handle OCR of German blackletter letterforms…
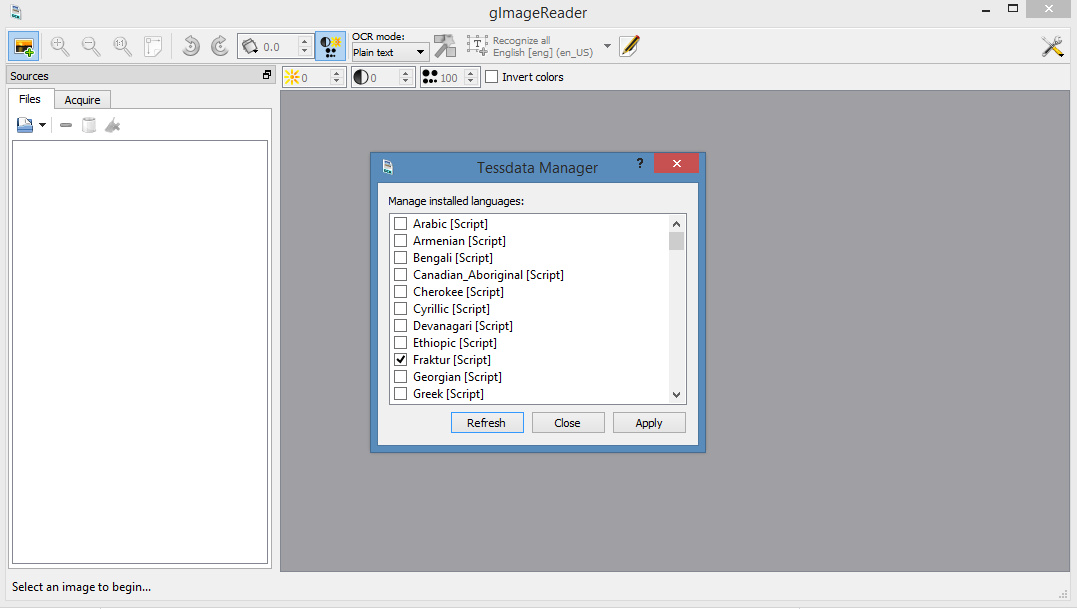
I’m assuming that gImageReader ‘knows’ where Tesseract 4.0 is, and hooks into it automatically. Because I didn’t need to set any file-paths to it, in gImageReader.
Once gImageReader is set up and the Frankur toggle/icon is switched, even when taking a screenshot the OCR results were pretty good…
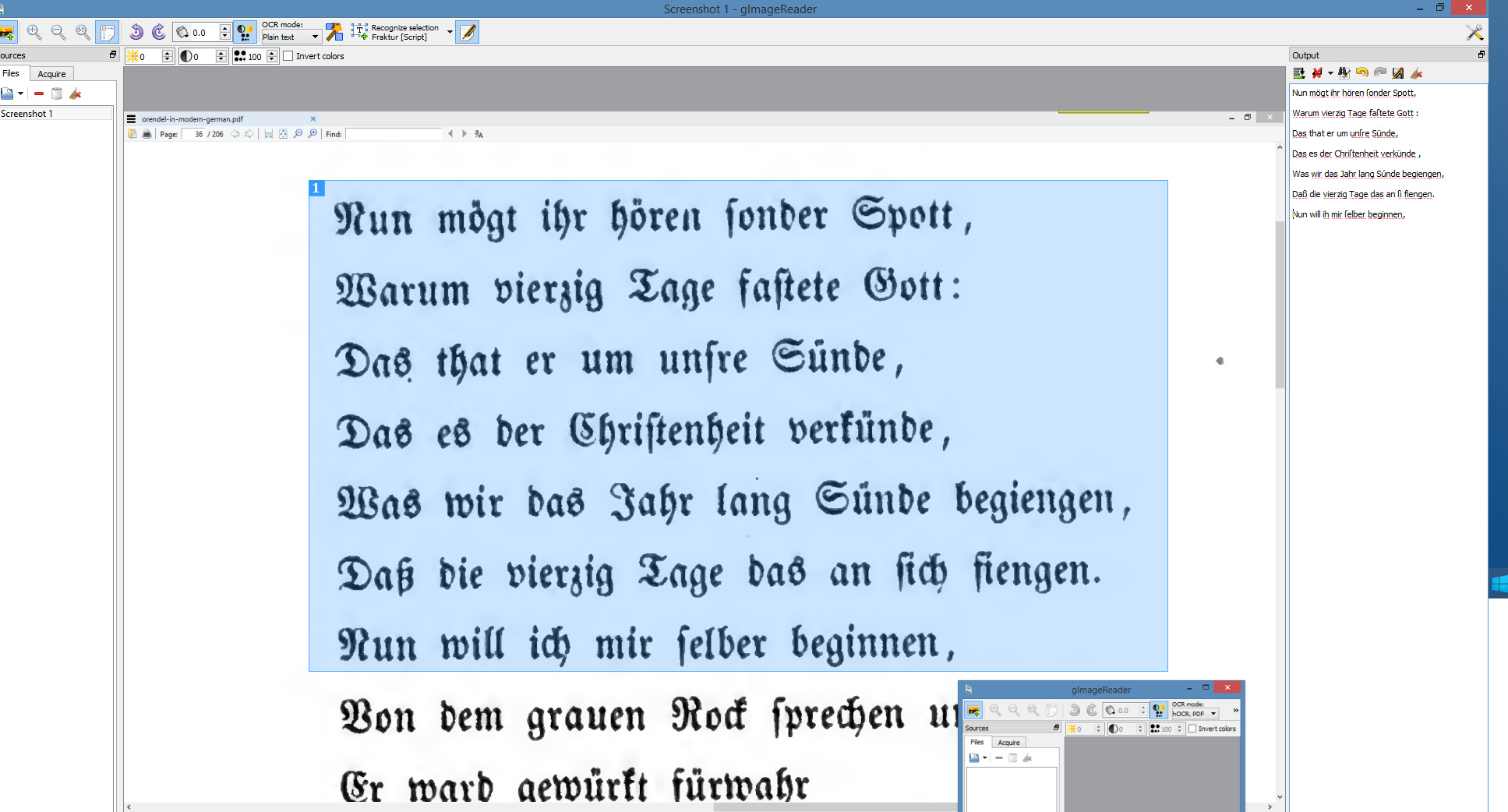
It can also handle complete PDFs, and seems to go at about 15 pages per minute on a modern desktop PC. Nice to have, and (in combination with Google Translate) useful if your research takes you back to the German literature of pre-1938 — but you can’t read German and certainly not in blackletter.
There are probably online sign-up services that can do the same, these days, where you do a sluggish upload and have to deal with time-outs and usage-quotas etc. But I prefer the ease of having one’s own Windows desktop software.
10 Thursday May 2018
Posted in JURN tips and tricks, My general observations
New to me: Google Translate now works on foreign-language PDFs. Perhaps it’s been available for a while, but I’ve seen no-one blogging about it.
It doesn’t work if you just right-click on the Web link to the PDF in, say, Google Scholar or JURN search results, and then select “Translate this page…”.
Instead you have to:
1) Right-click, and copy to the clipboard the direct PDF link.
2) Visit Google Translate, manually paste in the URL you just copied.
3) Click on the URL that appears over in the facing box.
4) The PDF text appears extracted, in the form of a Web page, and translated.
Very useful, and I had excellent results with a Polish article I tested. I had the whole article translated, too, not just the first few paragraphs. Longer items such as a PhD thesis will be refused as “too long”.
Note that a ‘redirect URL’, which gives the PDF but hides the direct URL link to the PDF, is of no use in the above workflow.
Sadly I guess it’s also a route to plagiarism for students. I’d suggest that the anti-plagiarism detector-bot services might usefully build a bank of Google-translated theses and dissertations, to add to their phrase-detection sources. Teachers who mark suspiciously-excellent final dissertations, and who are then inclined ‘to go on the hunt’, should also be aware of the possibility that the lacklustre student may have run a foreign dissertation through Google Translate and then lightly re-written it for clarity in English.
05 Saturday May 2018
Posted in Spotted in the news
Old-school point-n’-click videogame fun with the new free The Librarian, for Windows or Mac. The graphics style is deliberately retro (it’s a hipster thing).
[youtube https://www.youtube.com/watch?v=W81wa0VYlpI?rel=0&start=10&w=560&h=315]
05 Saturday May 2018
Posted in Spotted in the news
A new WordPress User Jargon Glossary, offering useful brain-jangling reminders in Plain English. Or, in WordPress-speak: ‘Post-Slug Pingbacks for your Metabox’.
04 Friday May 2018
Posted in Spotted in the news
A preprint, just arrived on SocArxiv: “Digital blackout of Spanish scientific production in Google Scholar”…
“An abrupt drop in the number of Spanish scientific journals covered in [since] the last edition of Google Scholar Metrics (2012-2016) has been detected. […] After considering several hypothesis to explain this phenomenon, we conclude that the main cause was the sudden disappearance of the Spanish bibliographic database Dialnet from Google Scholar.”
I’d add that parts of Ex Libris also summarily removed Dialnet in July 2017…
“all titles will be removed from Dialnet database in the Knowledgebase on July 20, 2017. The database will become a zero-titles database.”
This might suggest that the Google Scholar cut-out — apparently of some 2m Dialnet items — was just ‘an up-stream -> down-steam thing’ that flowed into Google Scholar. Due to the way they have their automated inputs set up from their partners? Just my guess.
04 Friday May 2018
GRAFT has just had another tranche of new URLs added to its index. Now searching across 4,640 university repositories, full-text and records alike.
03 Thursday May 2018
Posted in Spotted in the news
The Newberry Library has made its 1.7m images free to re-use, including commercial…
“users can share and re-use images derived from the library’s collection for any purpose without having to pay licensing or permissions fees to the Newberry. There are currently over 1.7 million Newberry digital images freely accessible online.”

Picture: Norman Rockwell, “Rosie the Riveter”, 1943. Not sure that Norman Rockwell is really public domain, but it’s nice to have in high-res.
03 Thursday May 2018
Posted in Academic search, Spotted in the news
New paper: “The discoverability of award-winning undergraduate research in history: Implications for academic libraries”, College & Undergraduate Libraries, April 2018…
“eight of the fifteen papers could be found in full text. If full text was available somewhere, Google always found it. Google Scholar only found four of the eight full-text papers […] Microsoft Academic found two of the full-text papers”
02 Wednesday May 2018
Posted in Spotted in the news
The BBC has released 16,000 sound effects for “personal, educational, or research purposes”, at BBC Sound Effects (beta). Format is .WAV. Search results were so fast that I didn’t initially realise that they’d been returned.
