BJHS Themes (British Society for the History of Science). Too new to be on the Google Search index, as yet.
+
PDF library of the Council for the Development of Social Science Research in Africa

31 Thursday Mar 2016
Posted in New titles added to JURN
BJHS Themes (British Society for the History of Science). Too new to be on the Google Search index, as yet.
+
PDF library of the Council for the Development of Social Science Research in Africa
31 Thursday Mar 2016
Posted in New titles added to JURN
Caribbeana : The Journal of the Early Caribbean Society
Journal of Glaciology (International Glaciological Society)
30 Wednesday Mar 2016
Posted in My general observations
I’ve been testing the English version of the major Russian search-engine Yandex for the last month. I’ve found it to be a useful alternative search engine, one with a surprisingly wide range and depth. In terms of the reach of its plain Web search I’d say it’s comparable with DuckDuckGo, though it can’t match the excellent relevancy-ranking of DuckDuckGo’s Image Search.
Other notable points are:
* it has ‘instant’ speed, as fast as Google Search.
* filters and search modifiers that are similar to Google.
* the user interface is easy to use and doesn’t annoy.
* there’s a pleasing lack of nag-nag-nag about EU privacy and cookies laws.
* it doesn’t throw a tantrum if you make more than a half-dozen site: searches.
For discovery of Web items from the “last 24 hours” / “last two weeks” Yandex is much less spammy than Google, making it much more useful for the few journalists and bloggers who actively go looking for timely new content. That’s true even when one runs Google Search with an extremely well-populated installation of Google Hit Hider by Domain (regrettably this Firefox/Greasemonkey addon, which automatically blanks spammy URLs in your search results in Google/Bing/DuckDuckGo, doesn’t yet support Yandex). A “last 24 hours” search in Yandex is also refreshingly free of Google’s “yeah, it’s actually from 2009, but we’re showing it because we crawled it again in the last 24 hours…” results.
When a 24-hour search is run on a timely in-the-news topic name or keyword, Yandex effectively becomes a very useful alternative to Google News or Bing News. It also accurately detects user-location (UK, city), without a sign-in, and correctly and deftly skews the news sources to the appropriate nation. Although there’s a caveat… on many keywords the first 10 results will often seem to skew toward the more left-leaning news outlets. I’d suspect the algorithm is just being unduly influenced by the clicks of a minority of heavy Yandex users, who will probably skew strongly toward people inclined to click on anti-western news headlines? I half-expected that the English version of Russia Today (RT) would rank highly, in that scenario, but it doesn’t seem to rank at all in such 24-hour search results. Not in the UK, anyway.
So Yandex’s Web search is impressive, but a little quirky in coverage. The largest gaps in Yandex’s coverage are due to sniffy sites that only allow the Googlebot to index their files. When Yandex is allowed to get in to such sites, the indexing and title identification of PDFs and articles seems directly comparable to Google Search.
I looked hard for browser add-ons for Yandex, but there are hardly any in English. A couple are worthy, though, and a search veteran working with Yandex would ideally want to…
1. Stop Yandex’s URL obfuscation in search results, with the browser add-on Google Search Link Fix (also works with Yandex).
2. Get a double-column layout for search results, if working on a desktop PC. There’s no version of GoogleMonkeyR that works with Yandex, but the Firefox add-on Stylish has a double-column UserStyle for Yandex that works fine.
Interestingly Yandex offers a sort-of Custom Search Engine. But your Yandex CSE and its topic have to pass moderation, and you have to admin the CSE from a single fixed IP. That’s no good at all for those who have a western-style ISP which dynamically assigns an IP address each session. I presume that Russian Internet users must be forced to have a fixed IP address.
Update, April 2016: a new and utterly dim-witted spelling auto-correction has been introduced. For instance “modal” is corrected to “model”, with no way of forcing the original term. eg: “modal” “wind turbine tests”. At a stroke, this makes Yandex unusable as an academic search engine.
30 Wednesday Mar 2016
Posted in Ecology additions, New titles added to JURN
British Studies Monitor (1970-1981 — apart from a couple of articles it’s bibliographic and dated, so it’s been added to the JURN Directory only)
Nauplius (Brazilian Crustacean Association)
+
Research papers of the International Atomic Energy Authority.
29 Tuesday Mar 2016
Posted in My general observations, Spotted in the news
I’ve found a rather good ‘intelligent speech’ podcast search-engine called Audiosear.ch. The public beta seems to have appeared last May, and it had some light publicity over the summer of 2015. At early 2016 Audiosear.ch is certainly better than any podcast search engine that I’ve ever seen, although it’s still very far from complete.

Audiosear.ch’s index is hand selected, with a strong focus on the top-ranking regular podcasts. So no swivel-eyed loons raving about vaccines and eugenics, or none that I could find. But the focus on mainstream popularity pushes Audiosear.ch strongly toward the shiny n’ slick American podcast format, and somewhat away from the in-depth academic (unless it has EconTalk-like levels of popularity – even then, only 14 episodes of EconTalk appear to be in the index). For instance, Audiosear.ch doesn’t index the excellent Astronomy Cast (now part NASA-funded) or The Long Now’s Seminars about Long-Term Thinking talks, though I’ve suggested both to the curators.
The user can filter Audiosear.ch search results by #LongListen (longer recordings), but can’t combine #LongListen with “by date”. So it’s not useful if you just want to drop by each month, to see what’s new-and-long on a small handful of your favourite topics. You can set up alerts, but you have to sign-up to get them and they sound very broad-brush…
“Get email alerts whenever a specific word or phrase is mentioned in a podcast that’s up on Audiosear.ch.”
They mean in the full transcripts. That’s likely to be useful for PR people, marketeers, and advertisers looking for suitable podcasts. Audiosear.ch no doubt now has a large and easily-monetised e-mail mailing-list of such people. But a regular listener might prefer to have an alert only if the keyword is in the title or the show-blurb. And to get the alert via RSS or Facebook.
Another problem is that the #LongListen tag doesn’t distinguish between magazine-style segmented shows that just happen to be long, and proper long talks / interviews / documentaries. So I’d suggest Audiosear.ch needs a “#LongListen BUT NOT #MagazineShow” search filter.
There’s no option for UK users to include the BBC Listen Again radio streams and then to make them searchable along with everything else. Which is understandable, given that the BBC sets arbitrary access time-limits, curtails region access, and doesn’t take adverts. Audiosear.ch can find one of BBC Radio 4’s most popular academic shows though, In Our Time — since the show’s household-name presenter has the clout to insist on always-accessible and globally-available .MP3 recordings.
I found a 40-minute November 2015 interview with the Audiosear.ch founder, on The Wolf Den (a trade podcast for the emerging podcasting industry), if you want to learn more about the background to the service and also its counterpart which archives radio transcripts. It seems that Audiosear.ch is seen as business-to-business by its curators, which explains its initial focus on very popular shows. The curators are also very Twitter-centric — which I’d suggest may be a stumbling block when pushing the podcast-listening habit out to older and wider audiences. Given that Audiosear.ch currently only has 136 Likes on Facebook, I’d suggest that Facebook could also use some love if and when they try to refine Audiosear.ch for consumers.
Finally, if you want an advert-skipable offline .MP3 from an Audiosear.ch result, rather than an audio stream, then note that Audiosear.ch URLs are supported for audio file conversion/download by the ever-reliable 9xBuddy.
27 Sunday Mar 2016
Posted in Spotted in the news
Sagnagrunnur is a mapped online database of Icelandic folk legends and fairy tales. ‘Ancient men’, Wizards, Elves, Sea-beings, Trolls and more, mapped and given citations on the dramatic terrain of Iceland. Possibly there’s also a secret wormhole to Gravity Falls in there somewhere.


The website also has a bibliography of the key scholarship on such topics, and a bunch of search and grouping tools sophisticated enough to require their own user manual.
27 Sunday Mar 2016
Posted in Ecology additions, New titles added to JURN
Press Start (videogame studies)
Interpretatio : Sources and Studies in the History of Science
CASI Working Papers (Center for the Advanced Study of India)
East Anglian Archaeology (monograph series, indexing out-of-print titles only)
Arthropod Systematics & Phylogeny
+
Publications of the International Growth Centre (project of the LSE and the University of Oxford)
26 Saturday Mar 2016
Posted in Ecology additions, New titles added to JURN
Davidsonia (University of British Columbia Botanical Garden)
+
Additional caches of research reports from WIPO and The World Bank.
24 Thursday Mar 2016
A major new consultancy report, “How Readers Discover Content in Scholarly Publications” (March 2016)….
* “… people working in the Government, Corporate and Charity sectors think Google is the most important discovery resource for books.”
This sentiment would have been rather more pronounced, if the Google respondees had been bundled with those who favoured Google Books.
* “… people working in Humanities and Religion & Theology prefer to use Google [rather than Google Scholar, to find articles]”
* “… people in Humanities are much less likely to use ToC alerts [to find their ‘last article accessed’] and have “other sources” they may use.”
Wide-spectrum serendipitous ‘topic search’, of the sort enabled by JURN, is also strongly favoured in the Humanities….
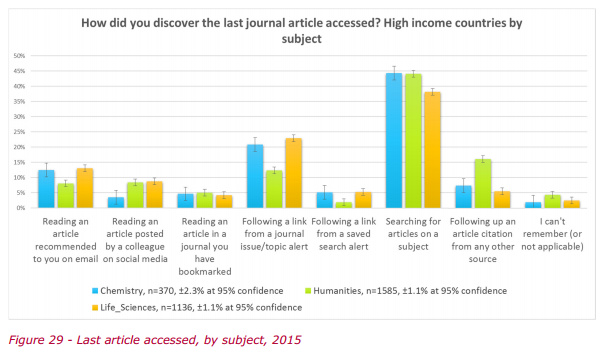
And the researchers found that…
* “Librarians behave quite differently to everyone else in search, preferring professional search databases and library-acquired resources.”
24 Thursday Mar 2016
Posted in Spotted in the news
A UK Parliamentary committee is undertaking a science communication inquiry. The deadline for written submissions is Friday 29th April 2016. There are also Parliamentary inquiries ongoing into A.I., Big Data, regulation of the Life Sciences, the UK science budget, and ‘science in emergencies’.