Removed Palgrave journals from the JURN index, since their generous offer of “all journal articles for free” during March 2014 is finishing today.
Palgrave removed
31 Monday Mar 2014
Posted in New titles added to JURN

31 Monday Mar 2014
Posted in New titles added to JURN
Removed Palgrave journals from the JURN index, since their generous offer of “all journal articles for free” during March 2014 is finishing today.
30 Sunday Mar 2014
Posted in Spotted in the news
New laws in the UK will soon mean that…
scientific Facts can be extracted and published without explicit permission [something that is set to become] law on June 1st.
The Shuttleworth Foundation has a concise round-up of the measures, plus Web links to the British government’s ‘plain English’ PDFs about the new measures. Oh, and that old-fashioned CD-ripping-to-MP3 thing becomes legal too.
30 Sunday Mar 2014
Posted in My general observations
Who is JURN for?
* independent scholars and researchers
* students and lecturers in developing nations
* unemployed or retired lecturers
* recent university graduates
* knowledge professionals outside of academia
* business leaders
* public policy makers and planners
* journalists and bloggers
* public intellectuals and ‘think tanks’
* evidence-based campaigners and activists
* amateur historians
* teachers of students aged under 18
* advanced and ambitious students, age 14-18
* home schoolers and grassroots educators
* adjunct or associate university lecturers, seeking a substitute for lost paywall access during the long summer holiday
* university lecturers and students, seeking a straightforward search tool for full-text open access content
28 Friday Mar 2014
Posted in JURN's Google watch, Spotted in the news
“A Google engineer has developed an algorithm that spots breaking news stories on the Web and illustrates them with pictures.”
28 Friday Mar 2014
Posted in Spotted in the news
Nearly 20,000 hi-res maps of America have been released under CC0 by The Lionel Pincus & Princess Firyal Map Division, The New York Public Library.
Here’s the press release, which has a download link to a free-registration download service containing the hi-res versions and also links to tutorials on how to use the service.
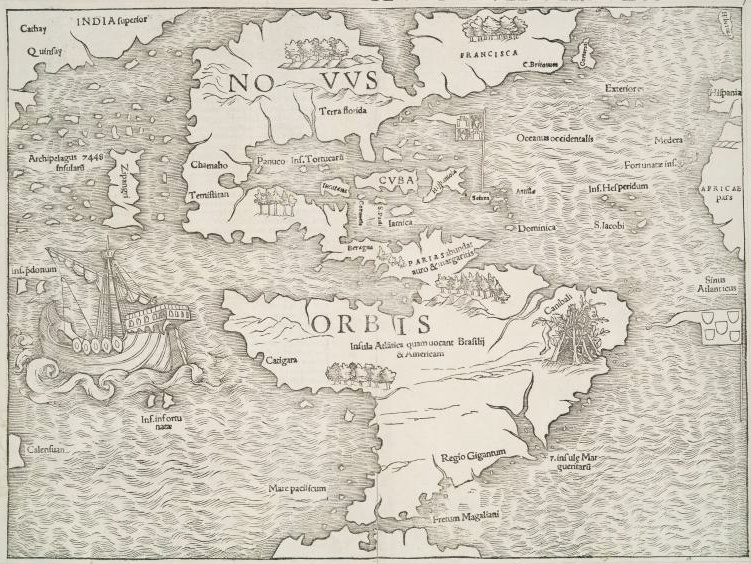
Above: America mapped, 1545.
27 Thursday Mar 2014
I had a quick look at the full list of Schema.org tags, which are now available in Google CSEs. They can be used to filter the CSE’s site list, serving to “Restrict pages from the above site list to only those that contain [chosen] Schema.org types”. Handy if you have a huge single site of HTML/CSS/XML that you can grep, and you want to prepare it for selective CSE search without having to juggle directories and file names.
It looks to me like those tagging open access scholarly articles would need to be able to chain Schema.org tags into something like…
CreativeWork: ScholarlyArticle: TransferAction: DownloadAction: GiveAction:
Whereas paywall publishers might need something like:
CreativeWork: ScholarlyArticle: TransferAction: DownloadAction: SellAction:
But at present there seems to be only the basic undifferentiated…
CreativeWork: ScholarlyArticle:
Even if there were workable OA additions to Schema.org, there would still the huge problems of: i) persuading people to add the tags to all their ongoing content at the article level, and to do so correctly and consistently; and ii) to have them go back and accurately tag perhaps two decades or more of existing open access articles.
26 Wednesday Mar 2014
Posted in Spotted in the news
From today, D&AD is offering free membership, which allows people access to an online archive of every ad to win a D&AD award [and] free copies of the D&AD annual

25 Tuesday Mar 2014
Posted in Spotted in the news
All the six-inch to the mile Ordnance Survey maps of Great Britain, 1842-1952. Now free, zoomable, and synced as geo-located historical series onto Google Maps.

It would be nice if they could get a system to extract all the keywords from the map lettering, rectify the (inevitably corrupted) keywords by fuzzy matching each of them against a standard historical gazetteer / place-name list for the area, then inject the hyper-linked names into each map’s page as keywords. That way the maps would be more easily searchable by keyword in Google Search. I’m not sure that’s even possible when old-style text is overlapping with graphical elements, as seen below, but it might be interesting to try…
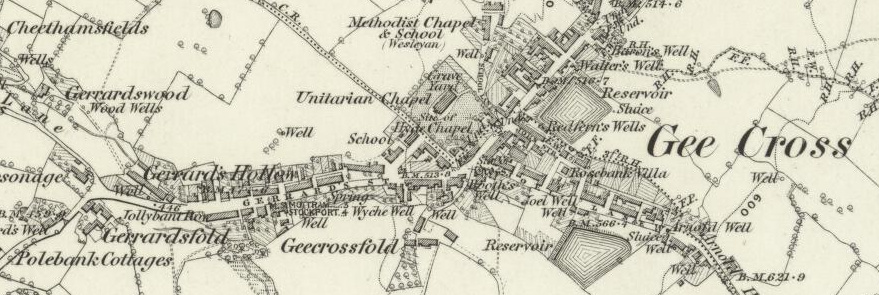
The modern names of places can, of course, already be looked up. But “Gerrardsfold” for instance, seen above in Cheshire, can only take one to a “Gerrards Fold Barn” in Lancashire when using the service’s modern lookup gazetteer.
25 Tuesday Mar 2014
The academic world recently learned that bots can write automated gibberish and — with a little help from their fleshy minions — can have it published in mainstream peer-reviewed scientific publications. But are we prepared for what follows from the moment when bots can reliably produce writing that makes real sense and which is useful and timely enough for use in major newspapers? It’s happening already. The finances of newspapers are such that a wave of robo-journalism seems inevitable, once we have a few more advances in semantics and automated basic fact-checking. Given the current dismal state of newspaper science reporting such new-fangled robo-news may even be slightly better than what we have now.
It follows that journal editors and publishers may soon need to add a new clause to their author guidelines, such as: “articles must be fully written by humans”. Not for fear of gibberish faux-papers, but rather because bots will be able to add sensible summaries and otherwise usefully aid in the writing of a research paper. Or we may need to develop an agreed form of simple presentation to flag up: [bot]this section of the text was written by bots[/bot] and to embed links to the bot’s sources.
Incidentally, I’ve also often thought that the humourous LOLcat language would form a pleasing basis for identifying messages-sent-to-humans by objects embedded in The Internet of Things, clearly marking their simpler forms of communications to us as being: ‘not kreated by th humanz’. We already have the LOLcat translation systems available.
25 Tuesday Mar 2014
Posted in Ecology additions, Spotted in the news
The Europeana Creative Challenge…
aim[s] to identify, incubate and spin off into the commercial sector viable online applications based on the re-use of digital cultural heritage content [from Europeana, and] The best five applications will be invited to a final challenge event to pitch their ideas to representatives from the cultural and creative industries as well as to investors.
The current challenge has a Natural History theme. Deadline: 31st March 2014.
Springing to mind: a simple workflow for automated extraction and smoothing of 3D shapes from high-res 2D photos of organic shapes (shells, fossils, wings, insects carapaces, etc), to create a royalty-free bank of organic starting-point shapes for rapidly iterative and generative product design prototyping.
 Chlamyphorus truncatus, via Europeana. The prototype for your new girls’ hairbrush has arrived… 😉
Chlamyphorus truncatus, via Europeana. The prototype for your new girls’ hairbrush has arrived… 😉